Recovery Simulation
Drop. Restore. Verify.
The Simulation
To prove the backup is valid I simulated a complete data loss event. I dropped the entire cancer_environment_db database and restored it from the backup file using the MySQL client. MySQL replayed all CREATE DATABASE, CREATE TABLE, and INSERT statements from the 2.18 GB dump file, rebuilding the database and all indexes from scratch.
-- Step 1: Drop the database (simulates data loss)
mysql --user=root --password --execute="DROP DATABASE cancer_environment_db;"
-- Step 2: Restore from backup
mysql --user=root --password ^
< cancer_environment_db_full_20260624_133040.sql
Post-Recovery Verification
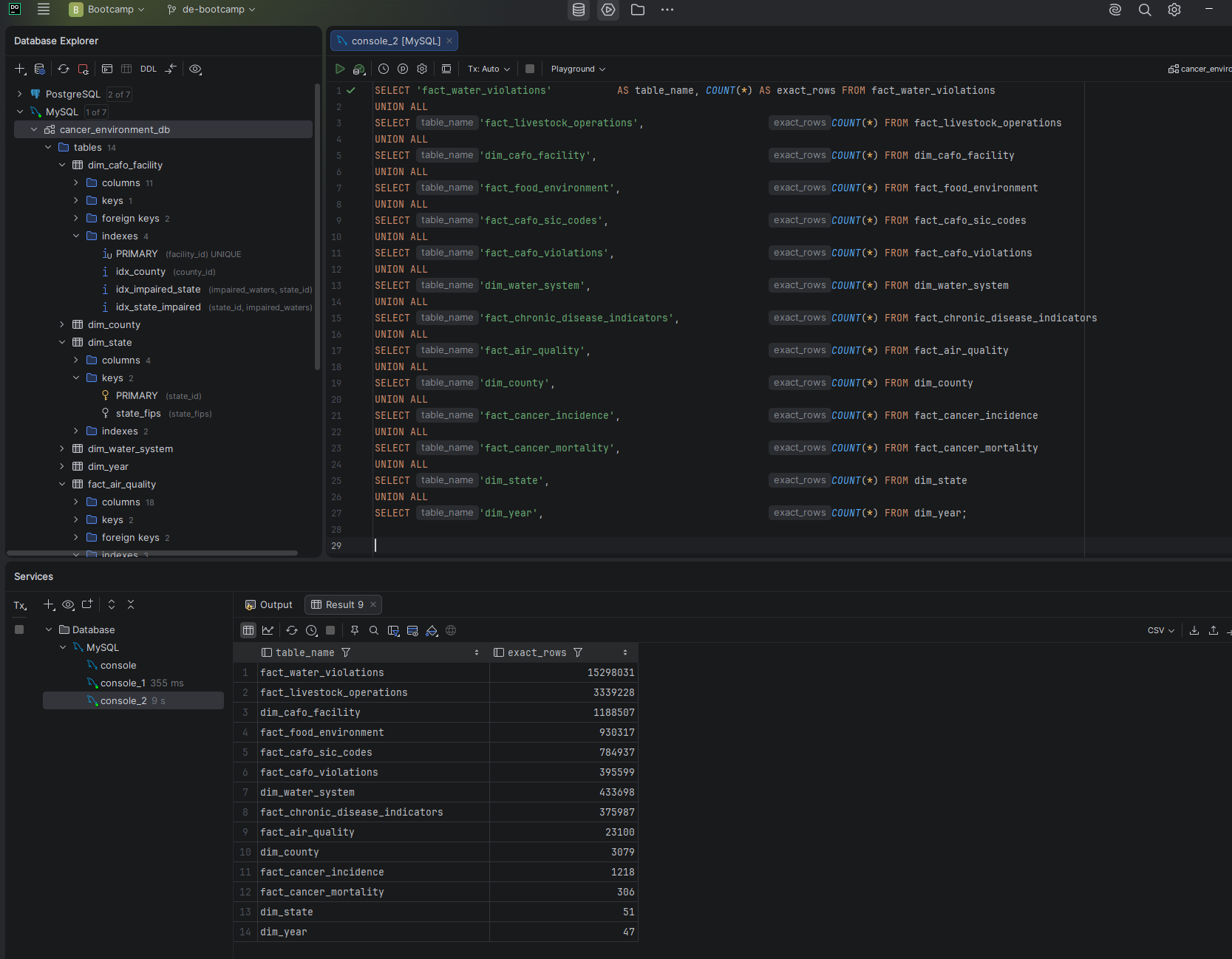
After the restore completed I ran exact COUNT(*) queries against all 14 tables and confirmed every row count matched the pre-recovery baseline. InnoDB's table_rows in information_schema stores estimates — exact counts require COUNT(*), which is what I used for verification.
Screenshot — Post-recovery row count verification
All 22,774,105 rows confirmed across all 14 tables after full restore from backup
| Table | Rows | Verified |
|---|---|---|
| fact_water_violations | 15,298,031 | ✓ |
| fact_livestock_operations | 3,339,228 | ✓ |
| dim_cafo_facility | 1,188,507 | ✓ |
| fact_food_environment | 930,317 | ✓ |
| fact_cafo_sic_codes | 784,937 | ✓ |
| fact_cafo_violations | 395,599 | ✓ |
| dim_water_system | 433,698 | ✓ |
| fact_chronic_disease_indicators | 375,987 | ✓ |
| fact_air_quality | 23,100 | ✓ |
| dim_county | 3,079 | ✓ |
| fact_cancer_incidence | 1,218 | ✓ |
| fact_cancer_mortality | 306 | ✓ |
| dim_state | 51 | ✓ |
| dim_year | 47 | ✓ |