Schema Design
Design Decisions & Rationale
Star Schema Structure
The schema uses four dimension tables — dim_state, dim_county, dim_year, and dim_water_system — as the stable anchors, with ten fact tables radiating outward for each measurement domain.
Decision 01
Star Schema over Flat Tables
The research question requires joining cancer rates to multiple environmental factors. A star schema makes these joins explicit, eliminates redundancy in dimension data, and makes the analytical query patterns predictable.
Decision 02
dim_county from USDA Census
I built dim_county from the USDA Census of Agriculture rather than a generic county list. Only counties with agricultural activity are included — a documented tradeoff that keeps the dimension grounded in real data rather than forcing artificial joins.
Decision 03
dim_water_system as Dimension
Water systems are modeled as a dimension rather than embedded in fact_water_violations. Each public water system serves a geographic area and has stable attributes — treating it as a dimension enables joining violations to counties and states cleanly.
Decision 04
Surrogate Integer Keys
All dimension tables use surrogate AUTO_INCREMENT integer primary keys rather than natural keys. This insulates fact tables from changes in source system identifiers and keeps join columns small and fast for a 22.7M row dataset.
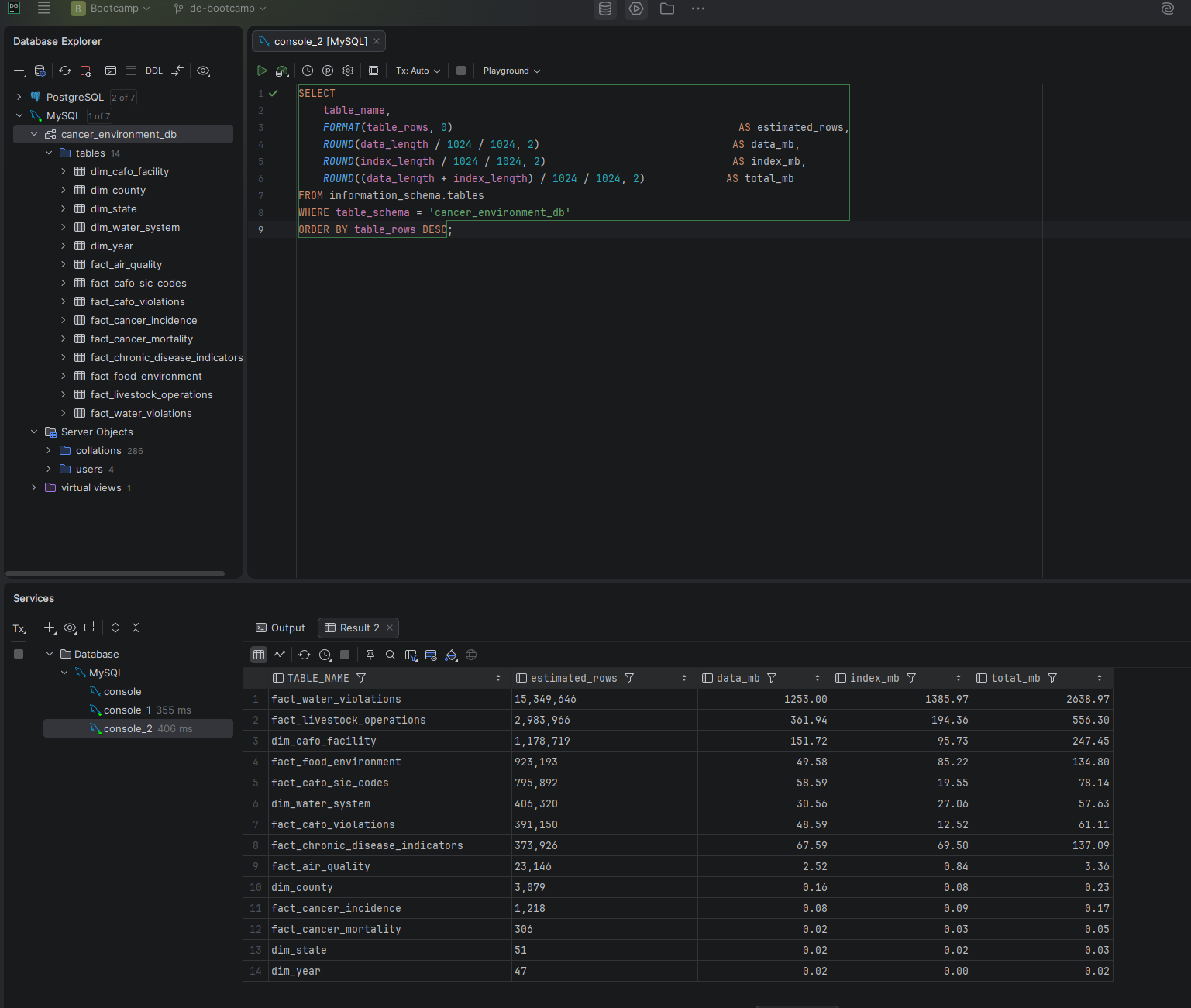
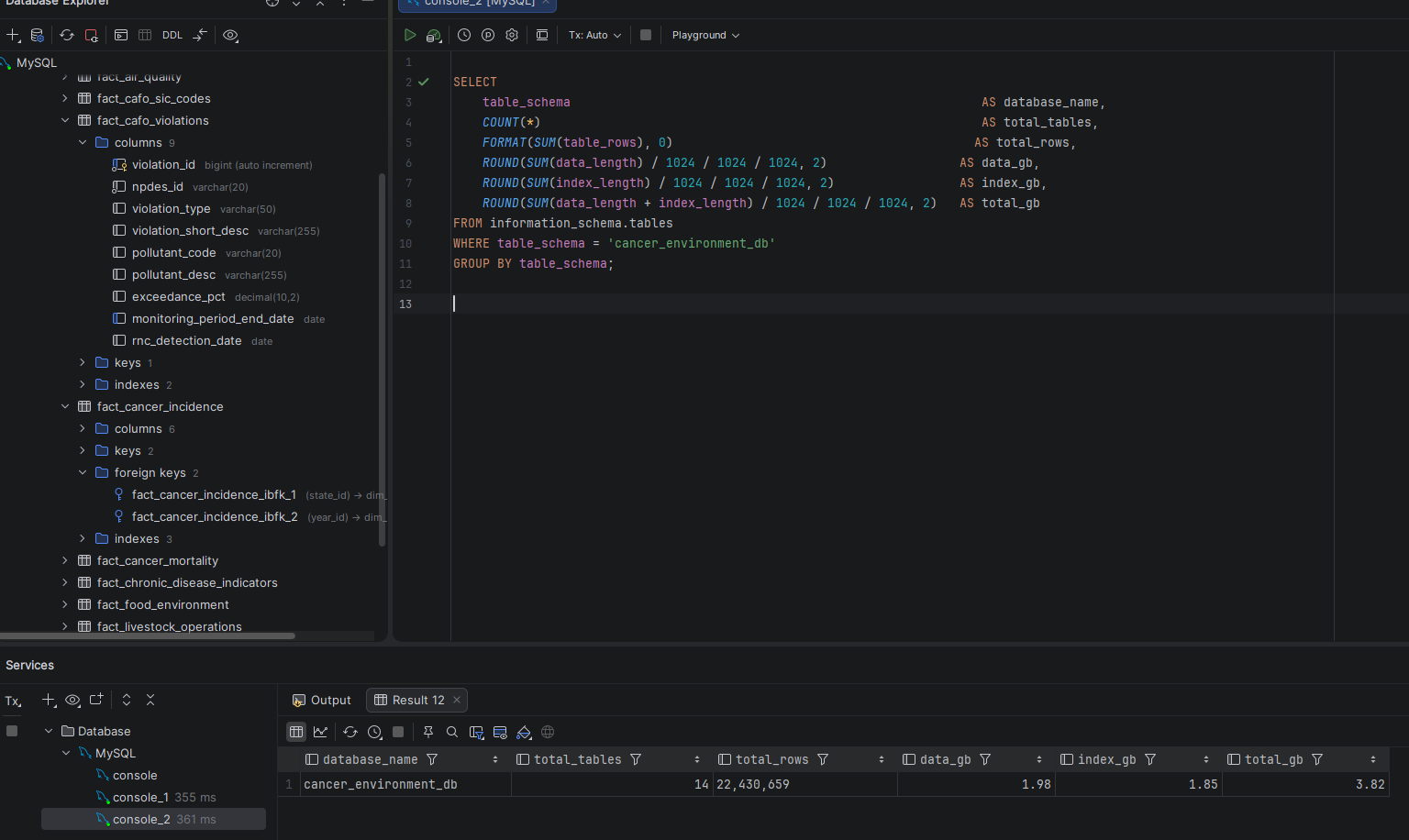
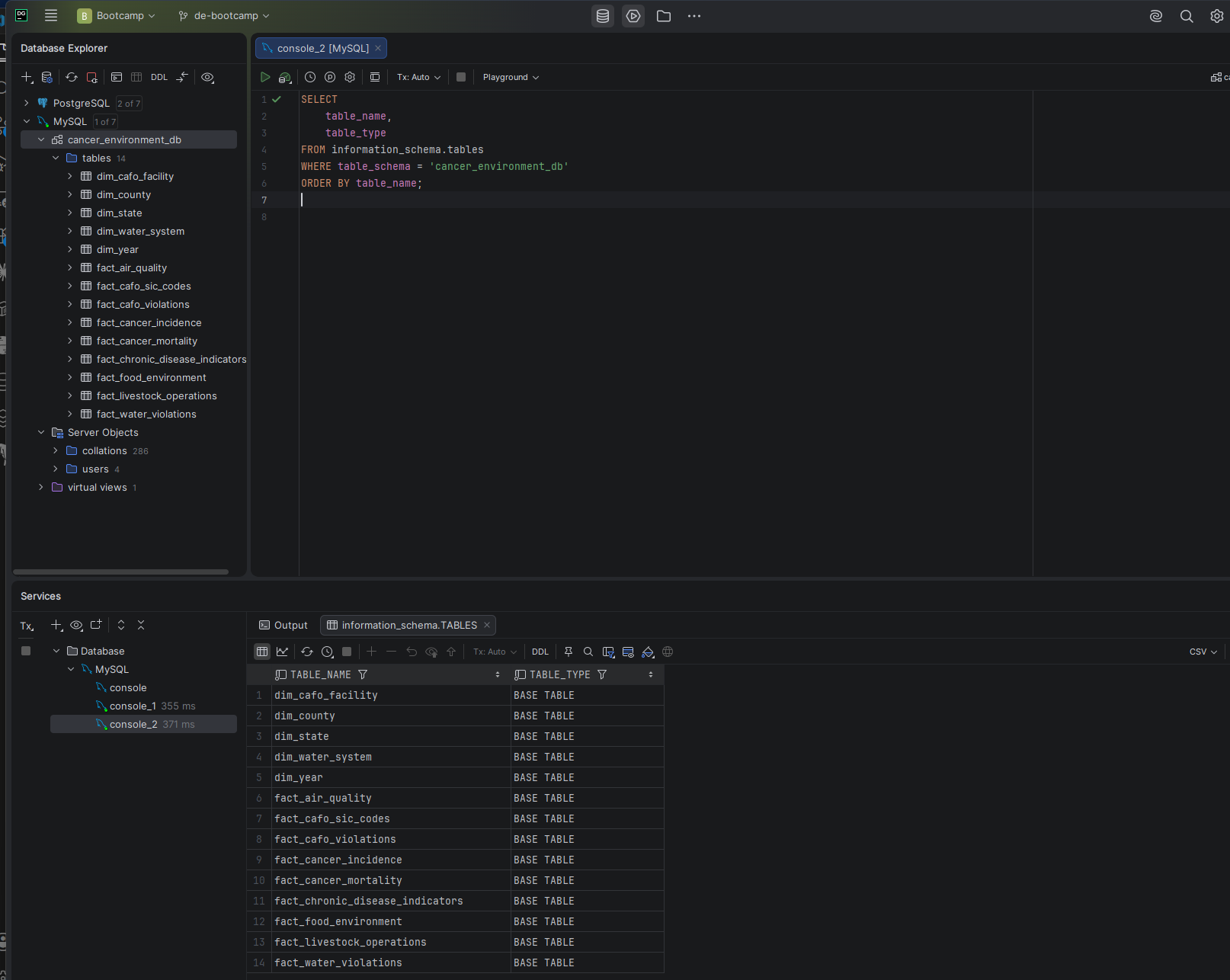
Screenshot — Schema overview in DataGrip
cancer_environment_db — 14 tables visible in the DataGrip database explorer