EXPLAIN Analysis
Q4 — The 9-Minute Query
EXPLAIN revealed that Q4 was performing a full nested-loop scan through all 15.3 million rows in fact_water_violations. The is_health_based_ind = 'Y' filter was being applied only after the join to dim_water_system and dim_state — meaning MySQL was joining the entire 15.3M row table before filtering it down to the health-based subset. The fix required a composite index on (is_health_based_ind, pwsid) plus a CTE rewrite to pre-filter before joining.
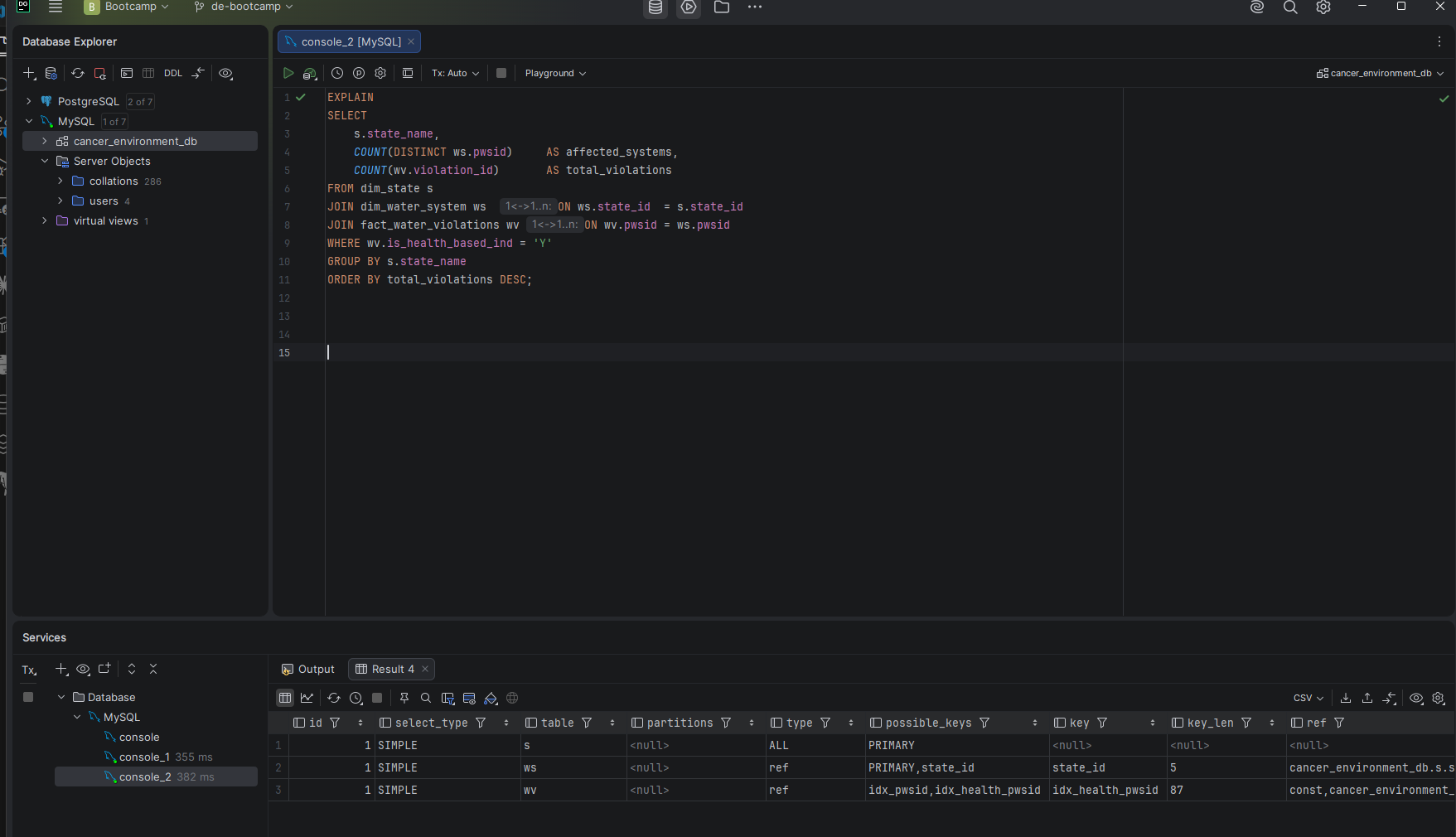
Q5 — The 4.6-Second CAFO Query
EXPLAIN showed Q5 was scanning all 1.18 million rows in dim_cafo_facility despite an existing state_id index. The optimizer ignored it because impaired_waters had very low cardinality — only two distinct values. With no index covering impaired_waters, the optimizer chose a full scan over the existing index. The fix required a composite index on (impaired_waters, state_id) with the correct column order.