Project Structure
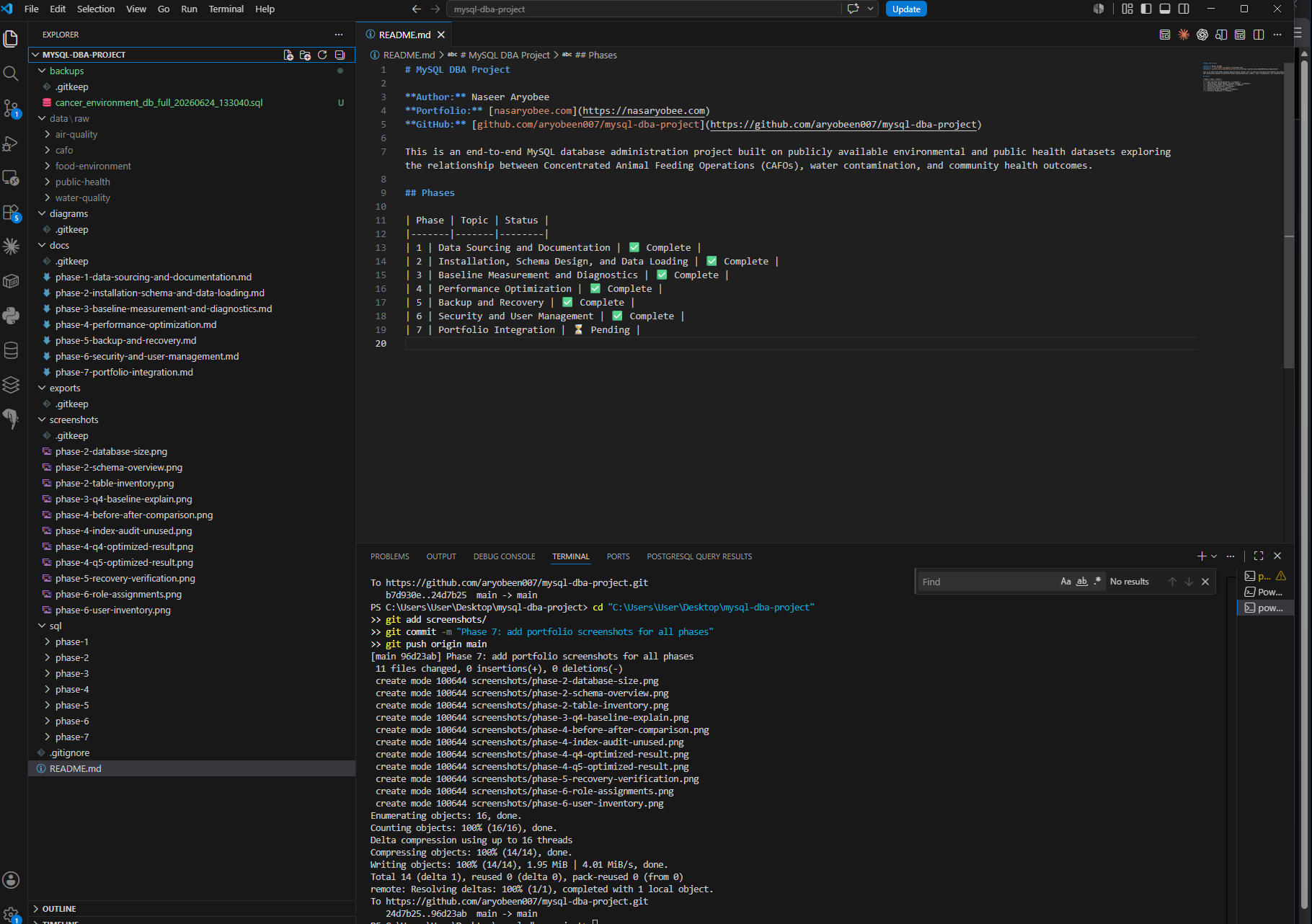
Repository Layout
Organized by Phase
The repository is structured so every SQL script, Python file, and documentation page maps directly to a project phase. Anyone reading the commit history can follow the project from data sourcing through schema design, optimization, backup, and security in chronological order.
Screenshot — Project folder structure in VS Code
Full project structure — sql/, docs/, data/, screenshots/, and backups/ organized by phase
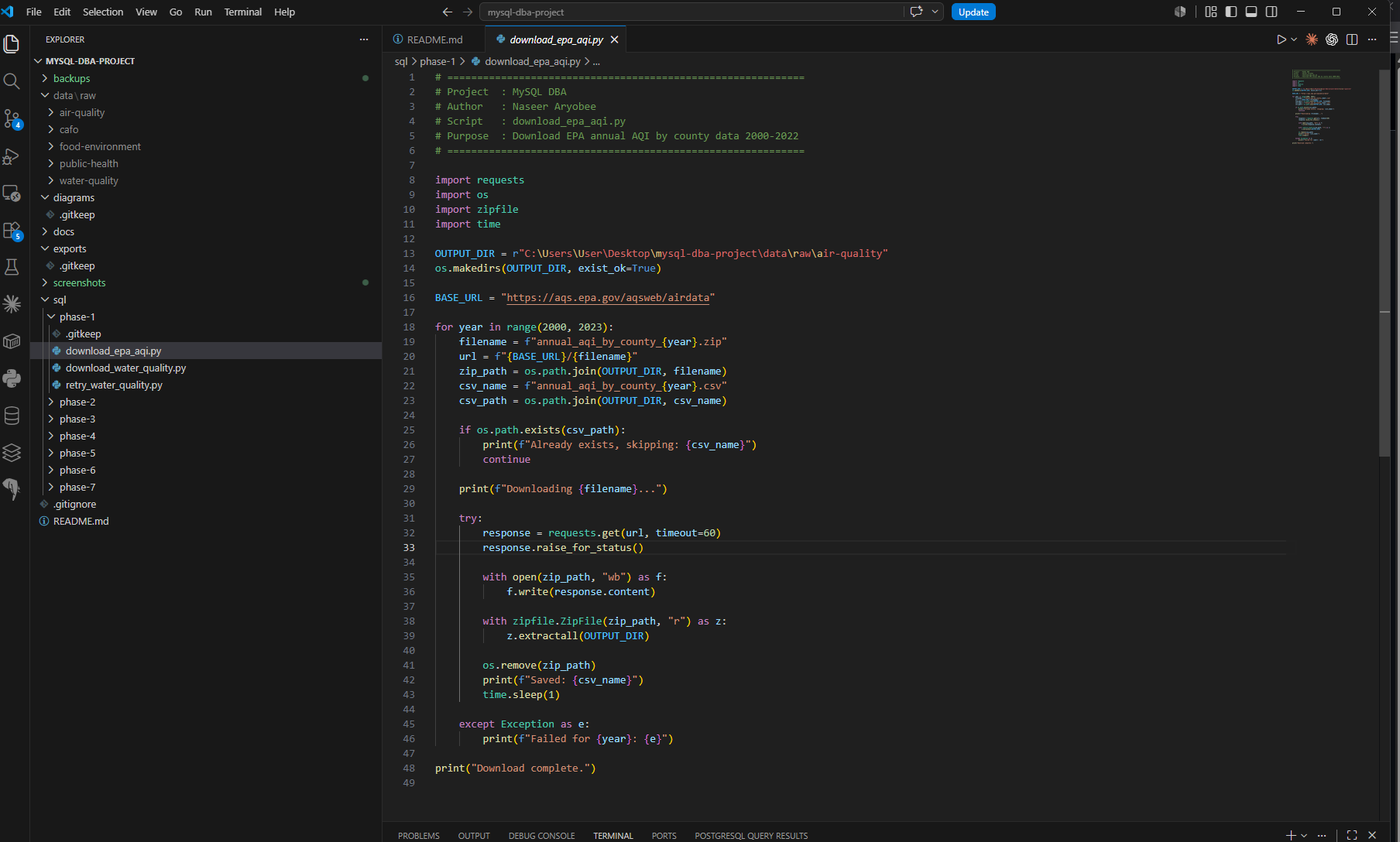
Screenshot — Python download scripts
download_epa_aqi.py — automated acquisition of 23 annual EPA AQI files