Query Rewrites
CTE & Subquery Pre-Aggregation
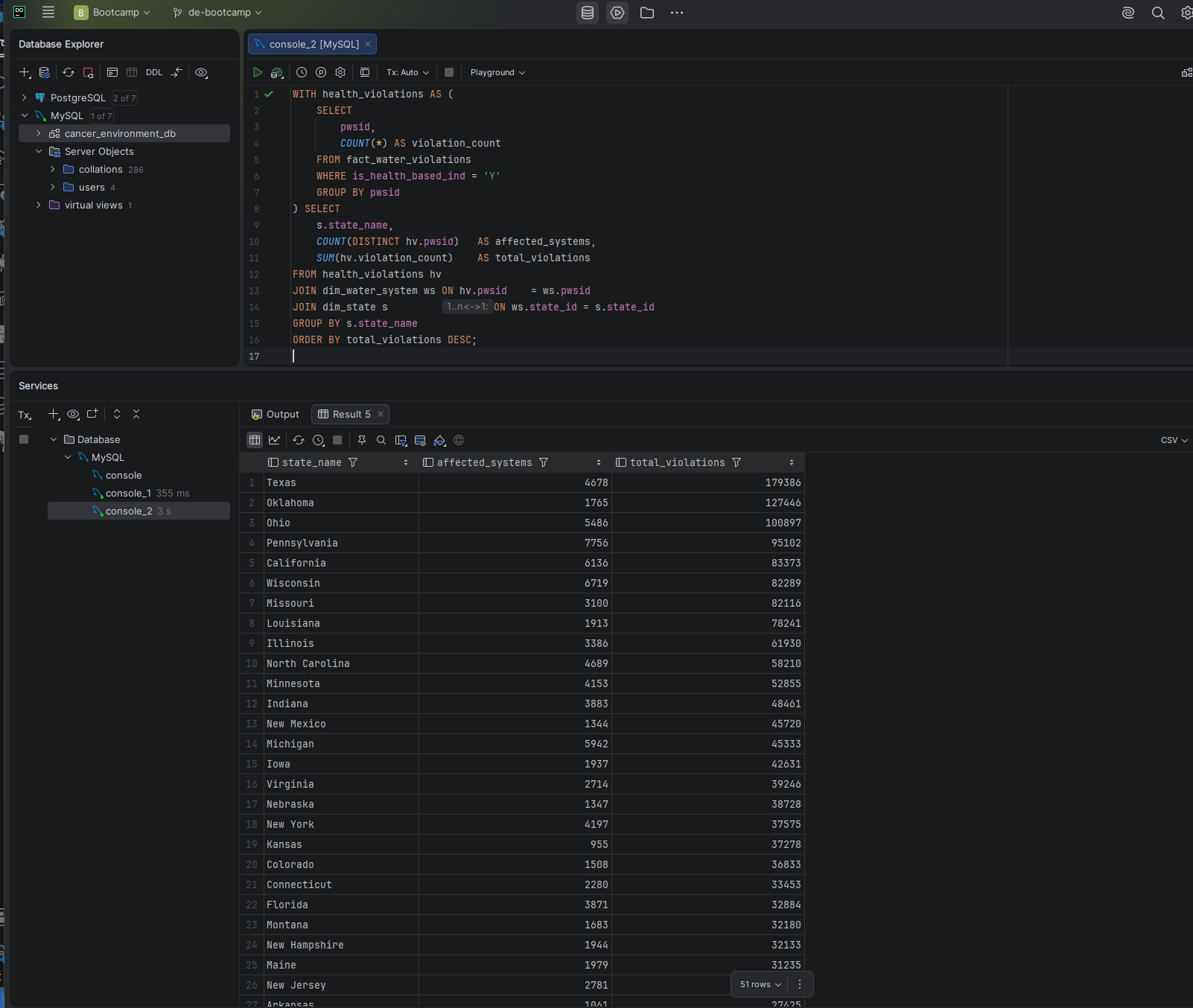
Q4 — CTE Pre-Filter
The original Q4 joined all 15.3 million violation rows to dim_water_system and dim_state before filtering. The rewritten query uses a CTE to pre-aggregate health-based violations by pwsid first — the optimizer hits the new index on is_health_based_ind, returns a small result set, then joins that small set to the dimension tables.
WITH health_violations AS (
SELECT pwsid, COUNT(*) AS violation_count
FROM fact_water_violations
WHERE is_health_based_ind = 'Y'
GROUP BY pwsid
)
SELECT
s.state_name,
COUNT(DISTINCT hv.pwsid) AS affected_systems,
SUM(hv.violation_count) AS total_violations
FROM health_violations hv
JOIN dim_water_system ws ON hv.pwsid = ws.pwsid
JOIN dim_state s ON ws.state_id = s.state_id
GROUP BY s.state_name
ORDER BY total_violations DESC;
Screenshot — Q4 optimized result
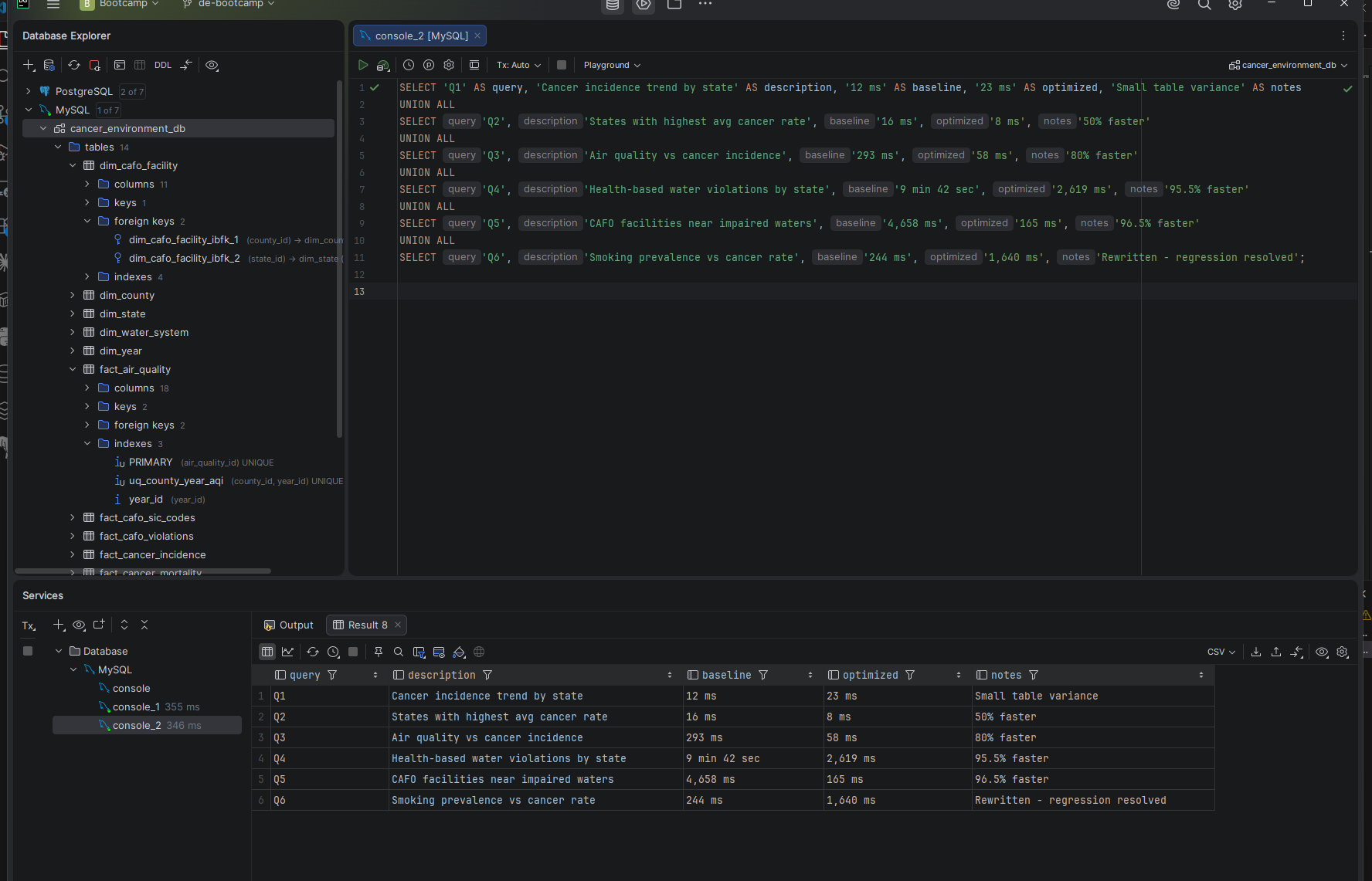
Q4 after optimization — 9 min 42 sec down to 2,619 ms. 95.5% improvement.
Q5 — Subquery Pre-Aggregation
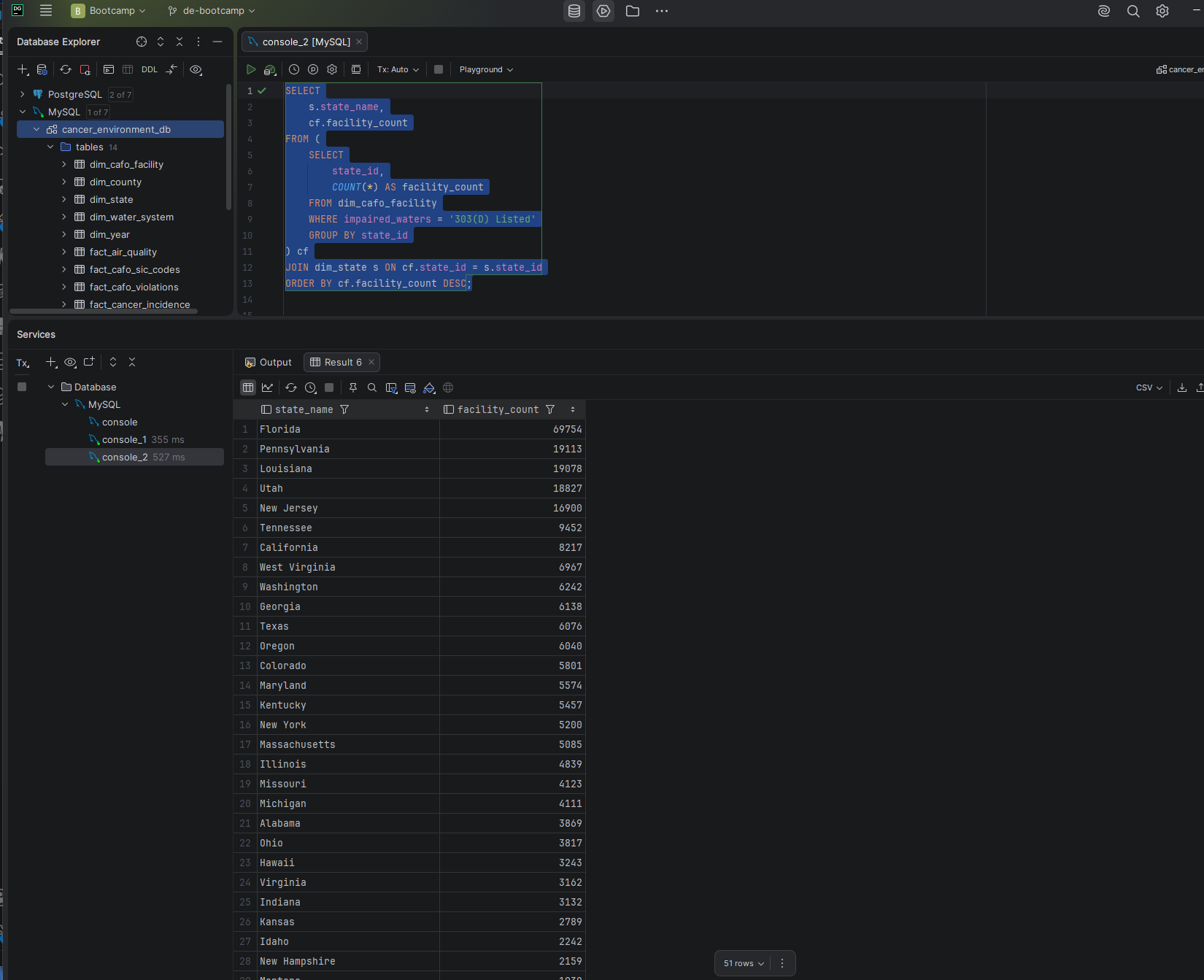
Q5 was rewritten to pre-aggregate dim_cafo_facility by state before joining to dim_state. I also discovered during testing that the impaired_waters column stores '303(D) Listed' rather than 'Y' — confirmed with a DISTINCT value check after Q5 returned 0 rows on the first run.
SELECT s.state_name, cf.facility_count
FROM (
SELECT state_id, COUNT(*) AS facility_count
FROM dim_cafo_facility
WHERE impaired_waters = '303(D) Listed'
GROUP BY state_id
) cf
JOIN dim_state s ON cf.state_id = s.state_id
ORDER BY cf.facility_count DESC;
Screenshot — Q5 optimized result
Q5 after optimization — 4,658 ms down to 165 ms. 96.5% improvement.