What This Project Demonstrates
The Goal
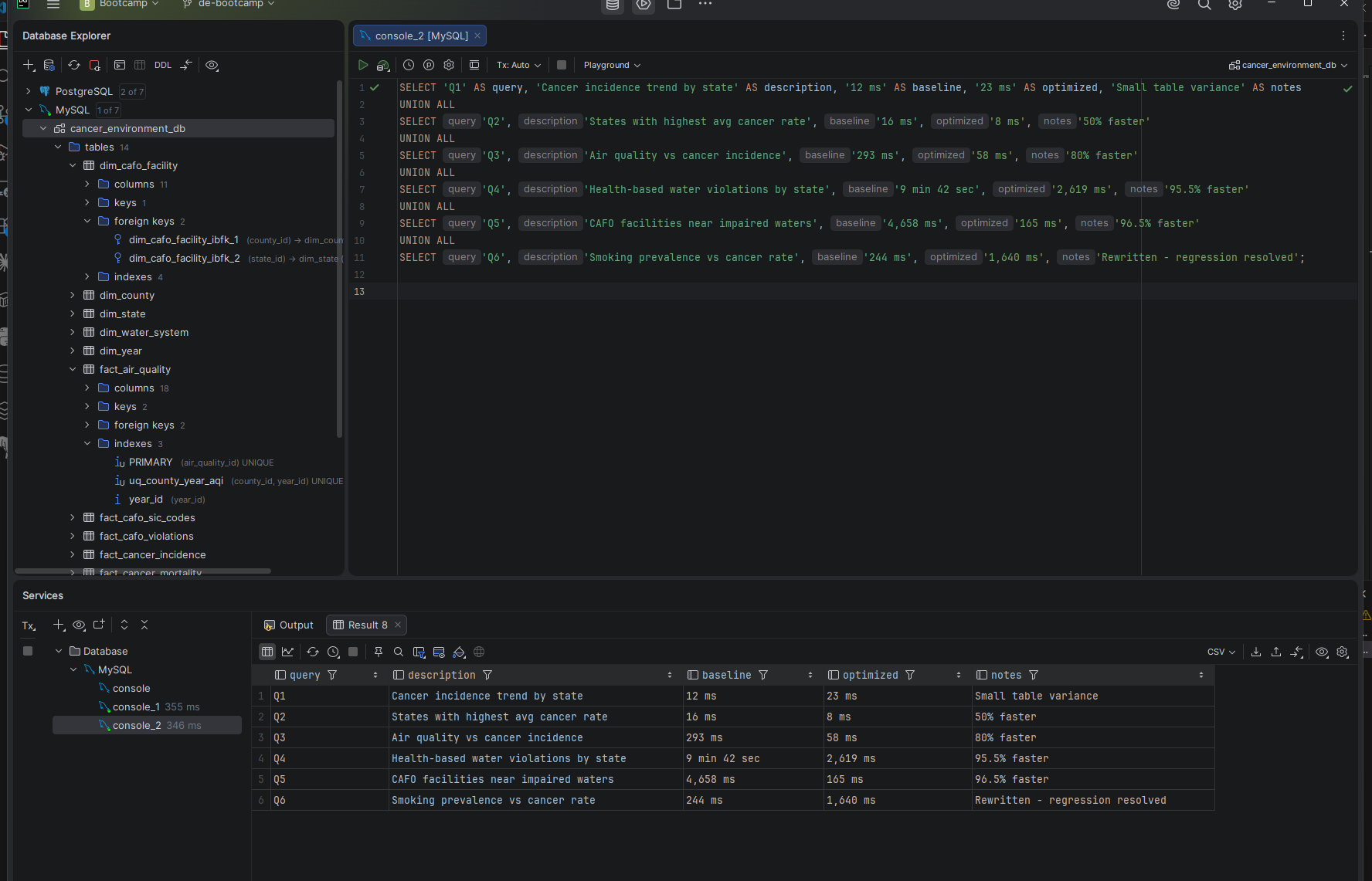
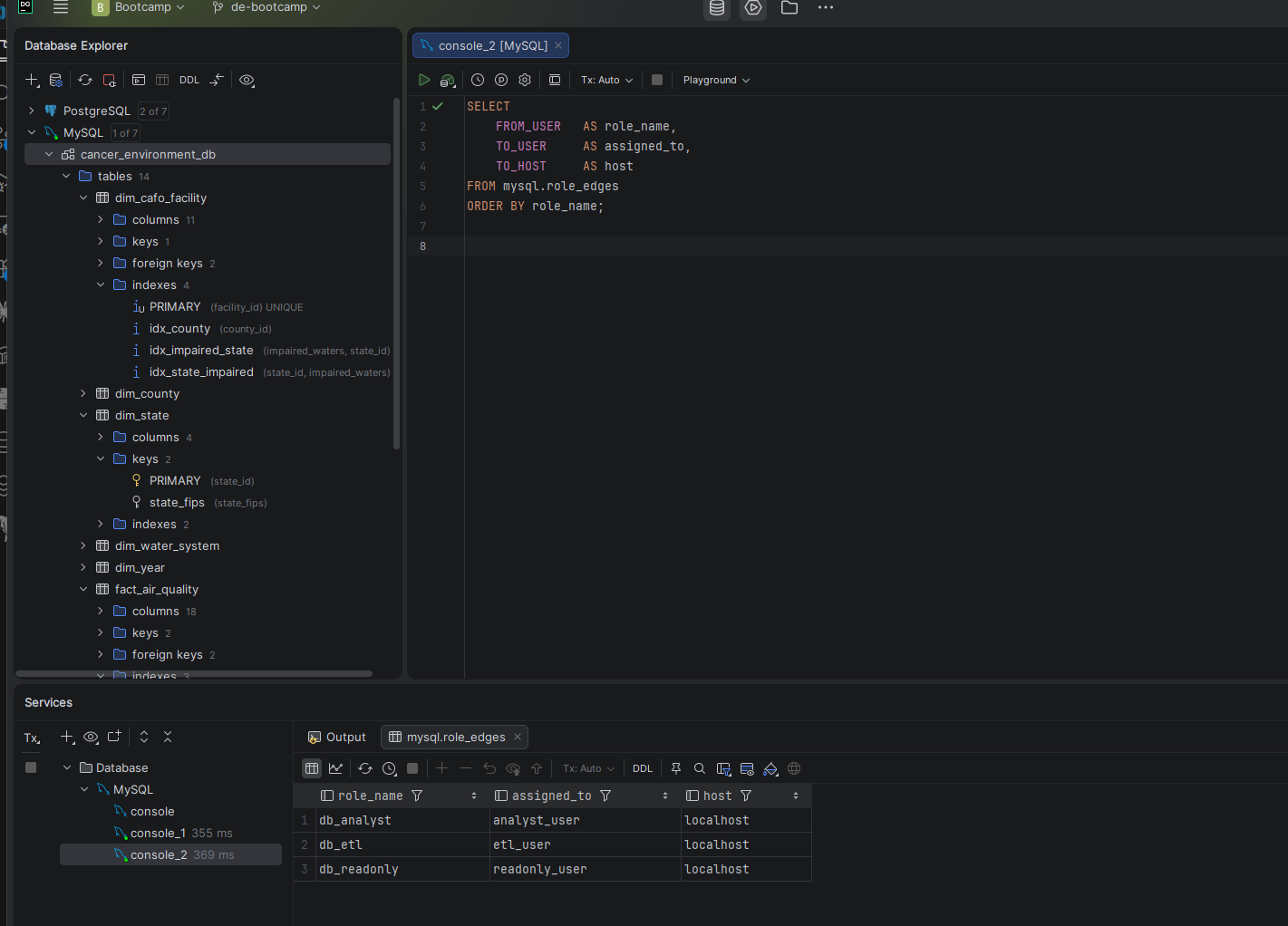
I wanted to build a MySQL project that covers the full scope of database administration — not just queries. Schema design, bulk data loading, performance baselining, index optimization, backup and recovery, and security aren't isolated skills. They form a complete discipline, and this project treats them that way.
The Dataset
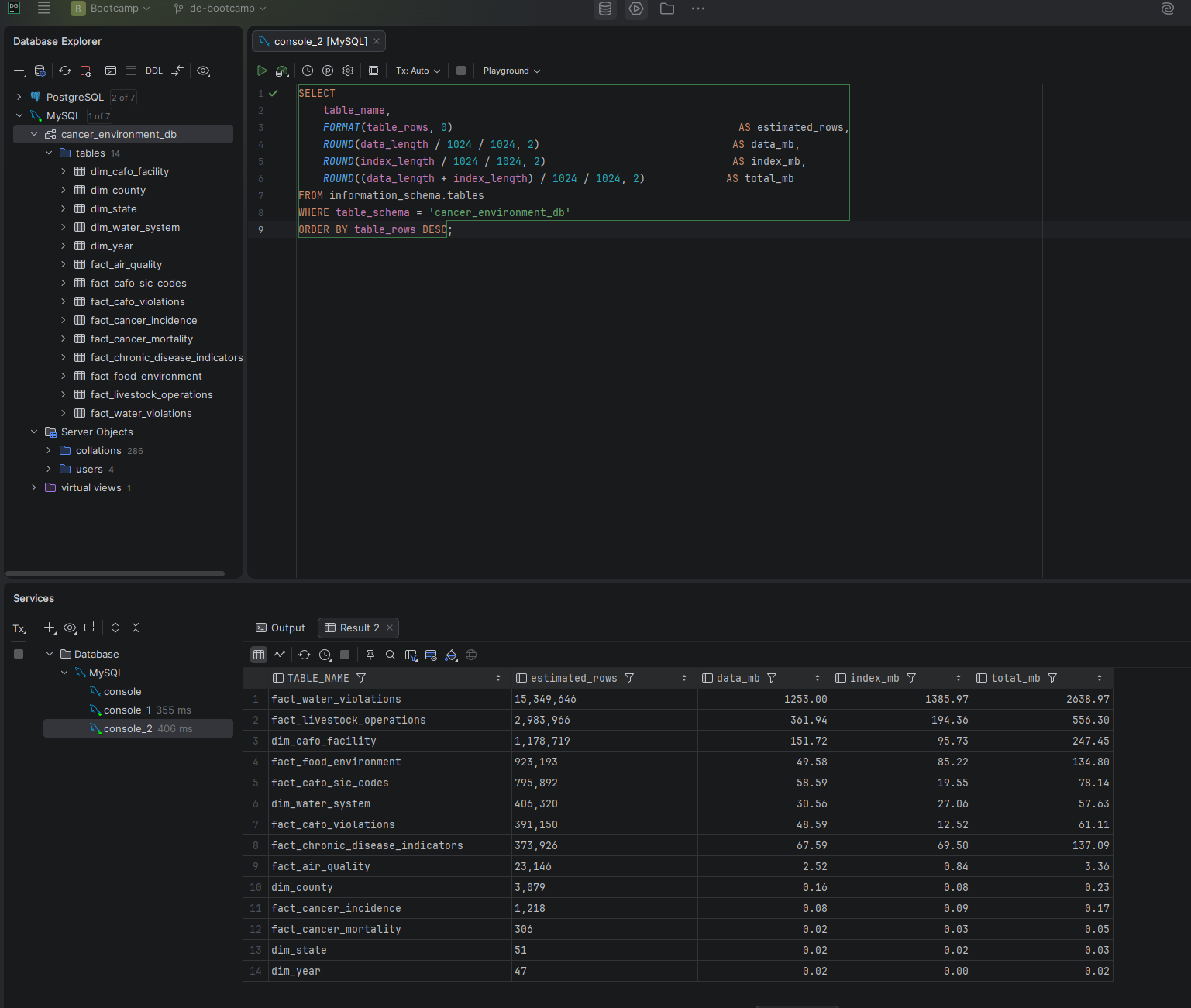
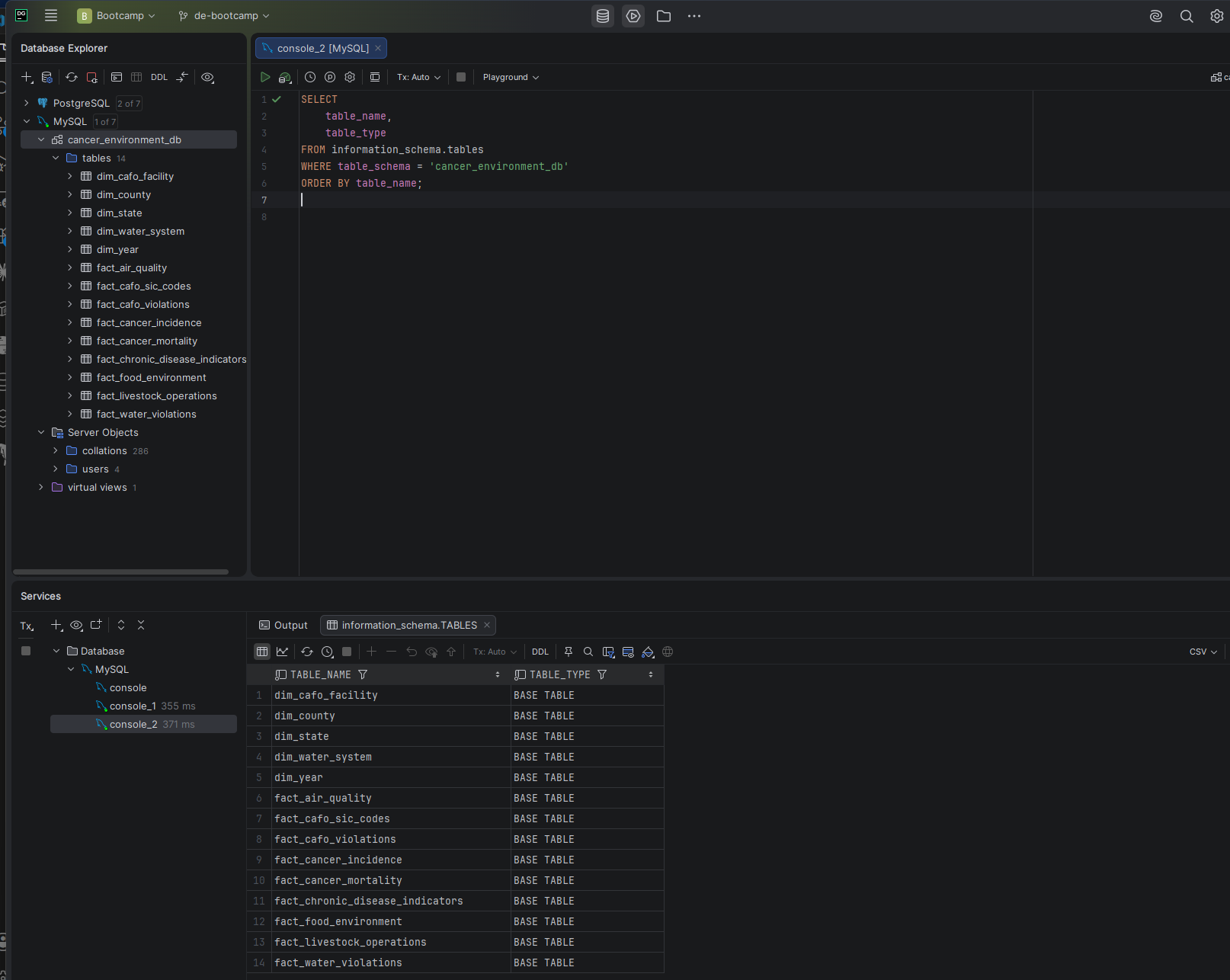
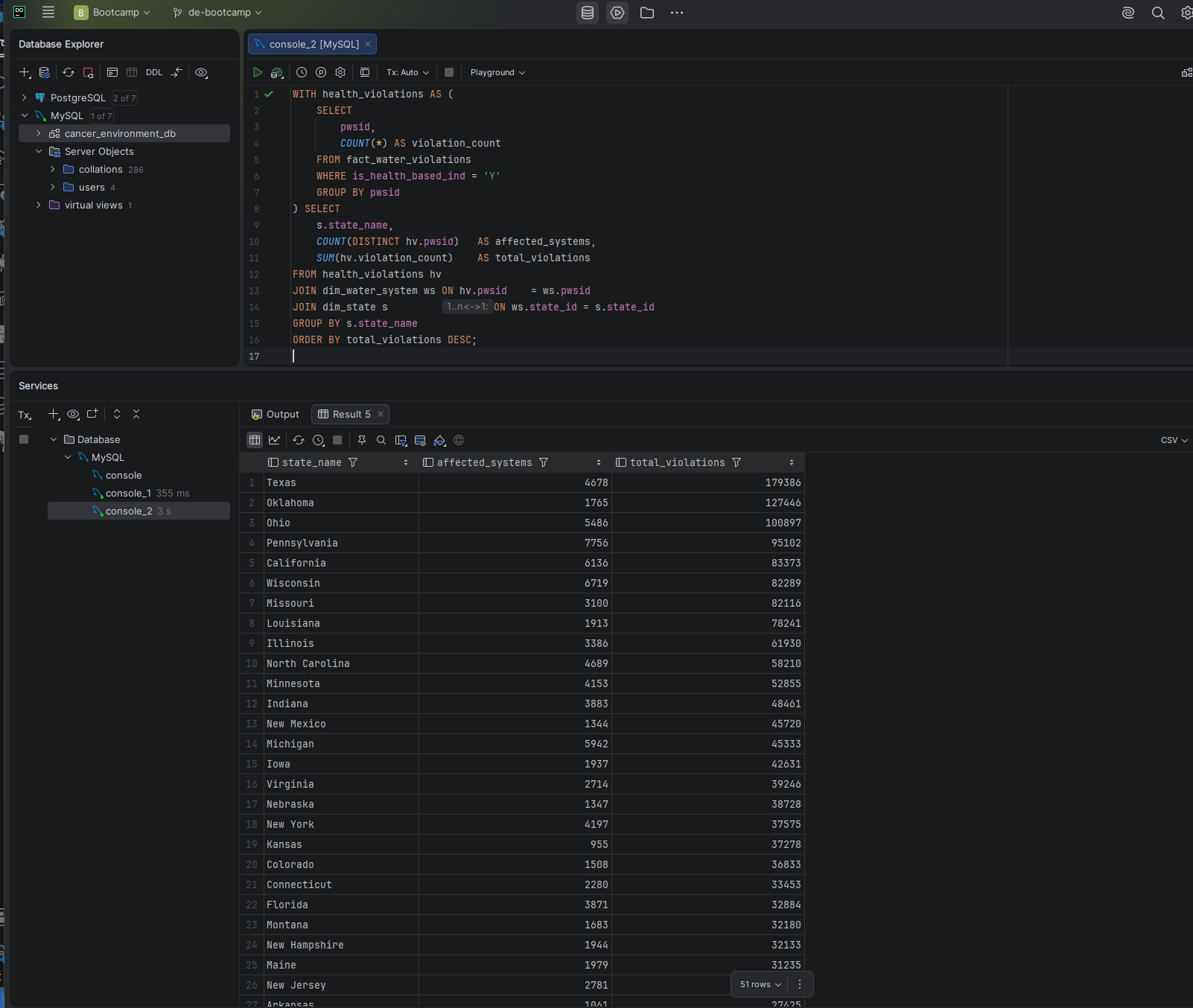
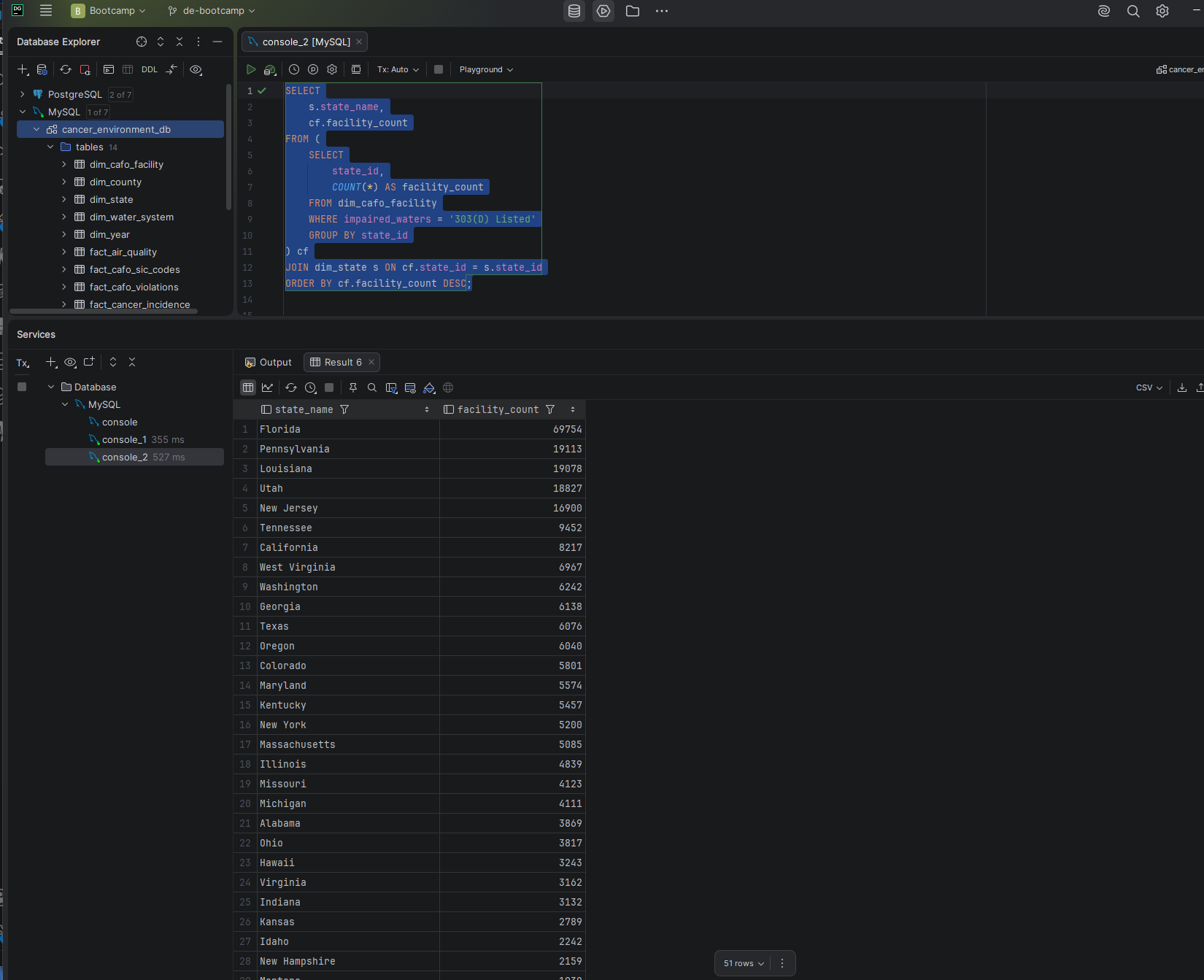
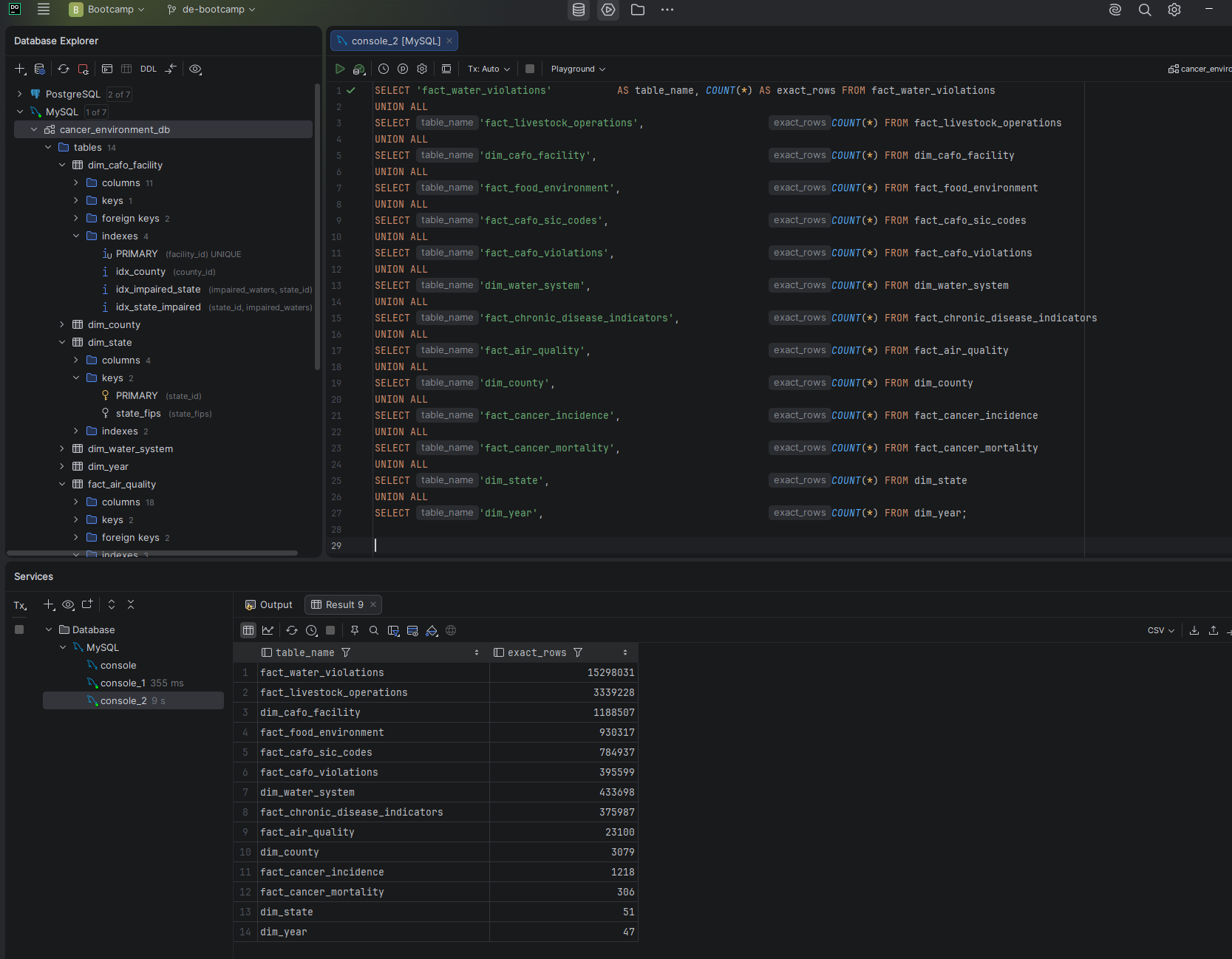
I used eight publicly available datasets from the EPA, CDC, and USDA to explore the relationship between cancer rates across the United States and contributing environmental, lifestyle, food, and water quality factors. The database covers cancer incidence and mortality, air quality, drinking water violations, food environment, chronic disease indicators, agricultural operations, and CAFO facility data — 22.7 million rows across 14 tables in a star schema design.
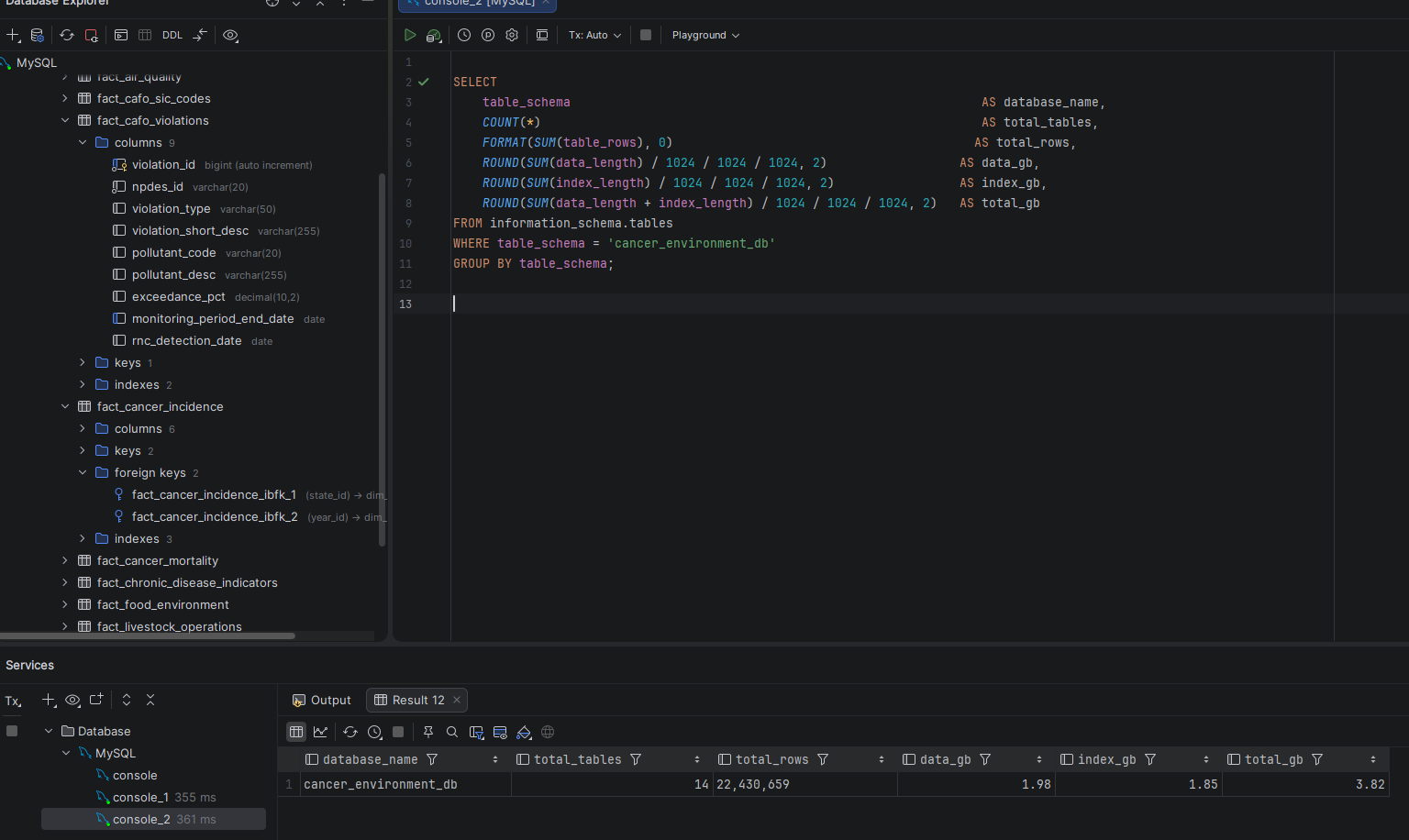
cancer_environment_db — 14 tables, 22.7M rows, 4.57 GB total