Routine Maintenance
VACUUM, ANALYZE & REINDEX
Why Manual Maintenance?
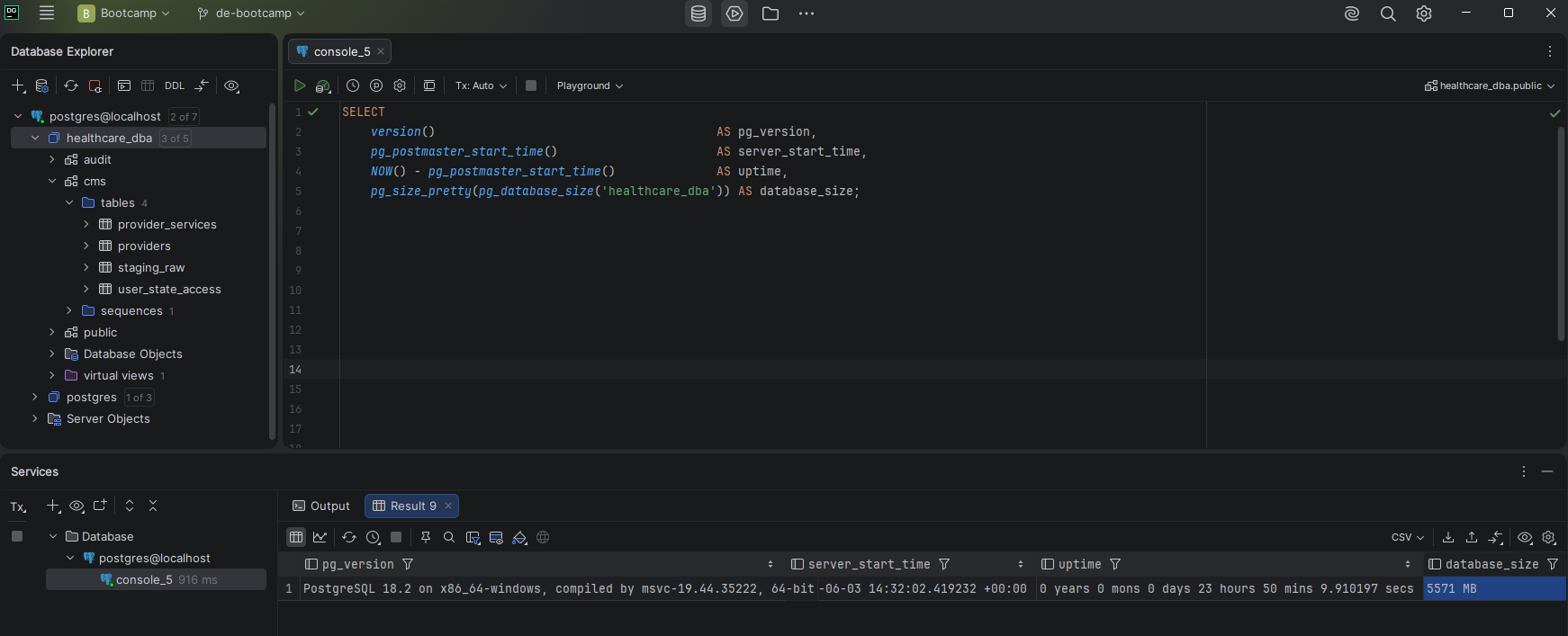
PostgreSQL's autovacuum handles routine cleanup automatically, but a DBA should also run manual maintenance after bulk data operations, before taking backups, and as part of regular operational procedures. I ran VACUUM ANALYZE on all three tables and REINDEX INDEX CONCURRENTLY on all five analytical indexes.
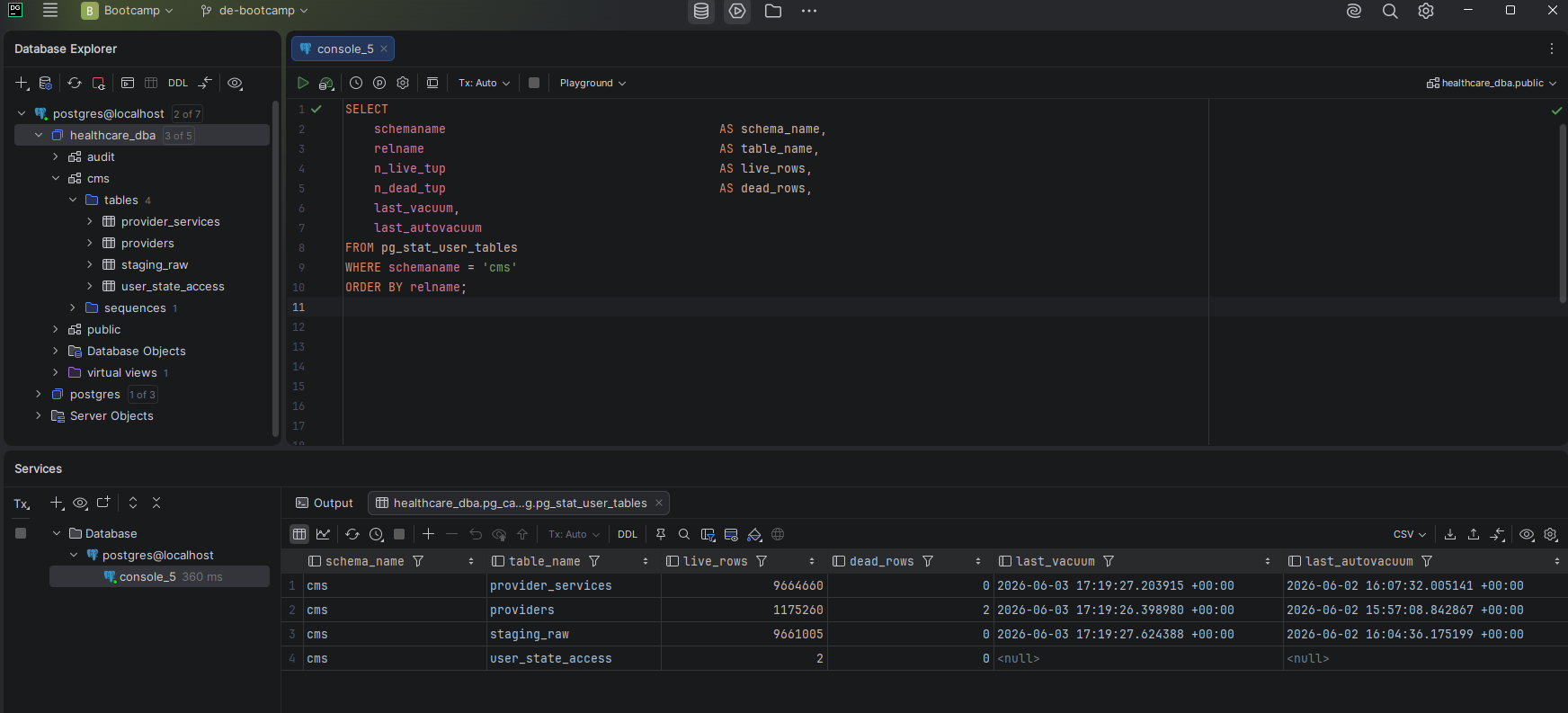
Screenshot — Table statistics after maintenance
Zero dead rows across all tables after VACUUM ANALYZE — last_vacuum timestamps updated to today's run
Autovacuum Configuration
| Parameter | Value | Meaning |
|---|---|---|
| autovacuum | on | Enabled — automatic cleanup active |
| vacuum threshold | 50 rows + 20% of table | ~1.9M dead rows triggers vacuum on provider_services |
| analyze threshold | 50 rows + 10% of table | ~966K row changes triggers analyze |
| vacuum cost delay | 2ms | Throttled to reduce I/O impact on live queries |