Index Strategy
Five Targeted Indexes
Why CONCURRENTLY?
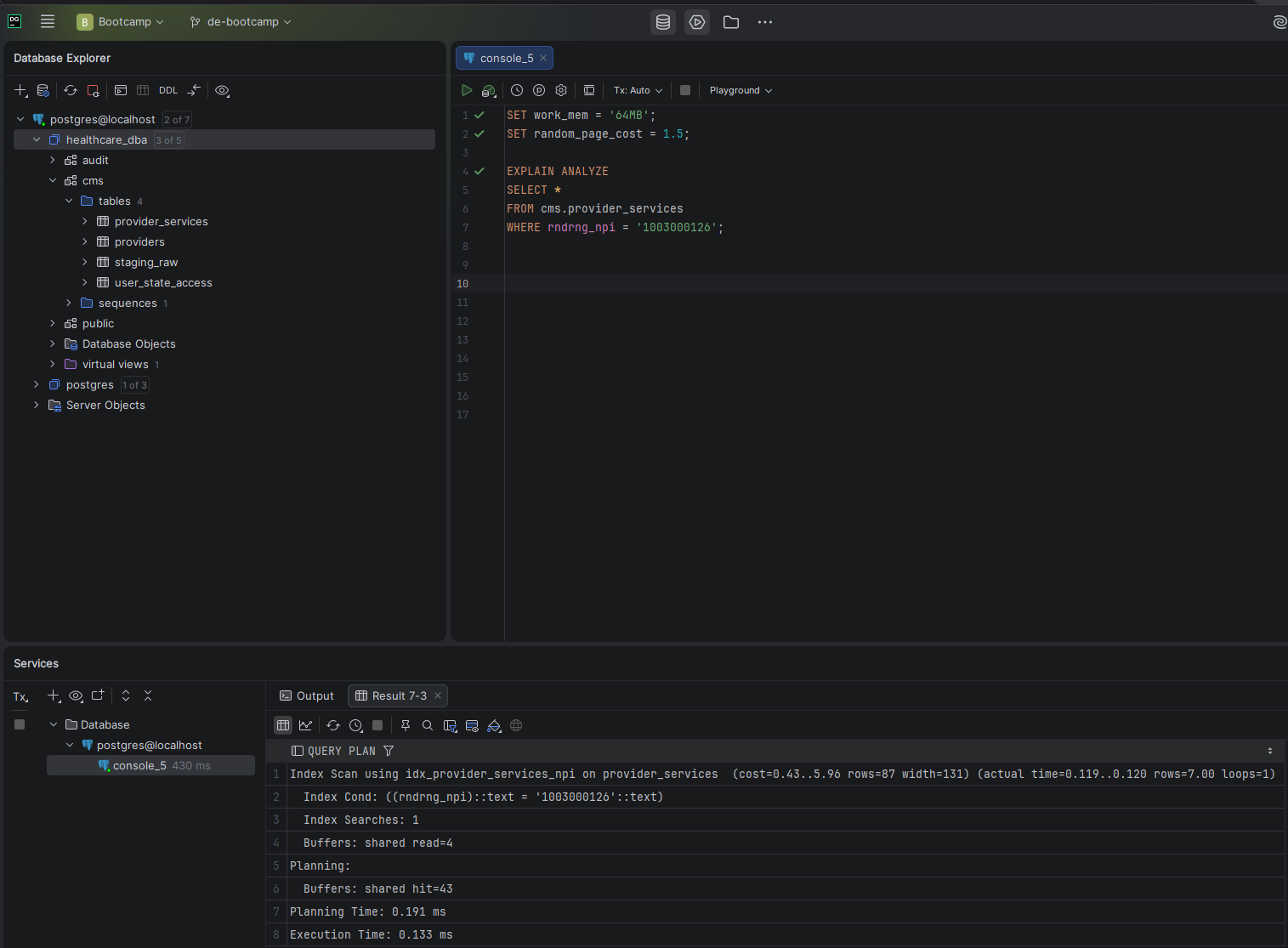
I created all indexes using CREATE INDEX CONCURRENTLY. This is the production-safe approach — it builds the index without holding a lock on the table, meaning reads and writes can continue uninterrupted during the build. On a table with 9.6 million rows, locking during index creation would be unacceptable in a live environment.
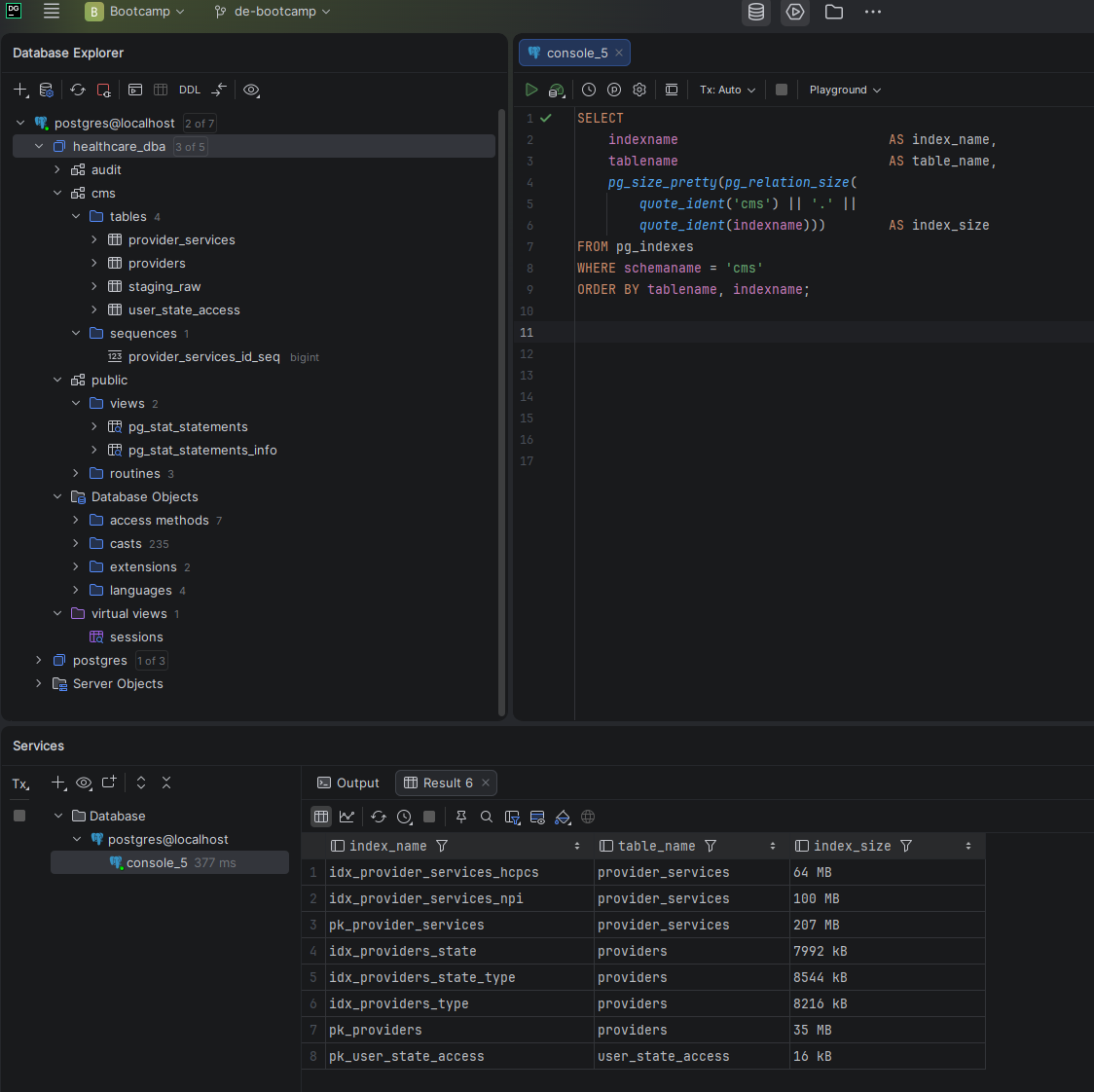
Screenshot — Index inventory after optimization
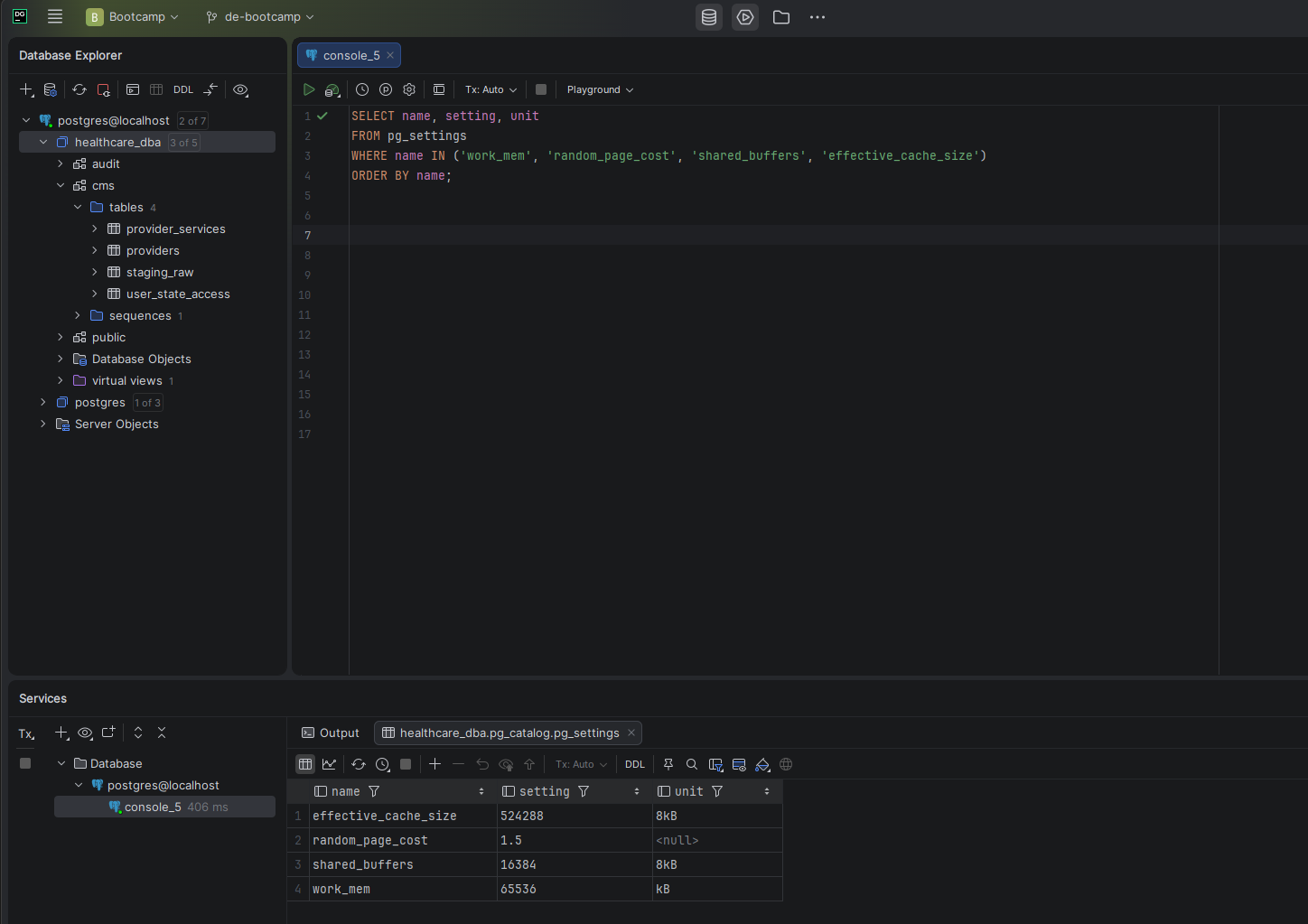
Seven total indexes — two primary keys plus five new analytical indexes targeting the columns identified in Phase 2
idx_provider_services_npi
The most critical index. Phase 2 showed Q2 scanning 3.2M rows to return 7 records because no index existed on this join column. This single index produced the 4,136× improvement.
idx_provider_services_hcpcs
Supports procedure-level aggregations. Q5 was sorting all 9.6M rows by HCPCS code with no index support — this index enables the planner to use more efficient access paths.
idx_providers_state
Supports geographic filtering on the providers table. Low-cost index on a 1.17M row table that enables efficient state-level filtering and sorting.
idx_providers_type
Supports specialty filtering and group-by operations on provider type. Complements the composite index for queries filtering on type alone.
idx_providers_state_type
Composite index supporting Q4 which groups by both state and provider type together. More efficient than two separate indexes for this specific query pattern.