Storage Baseline
Database & Table Sizes
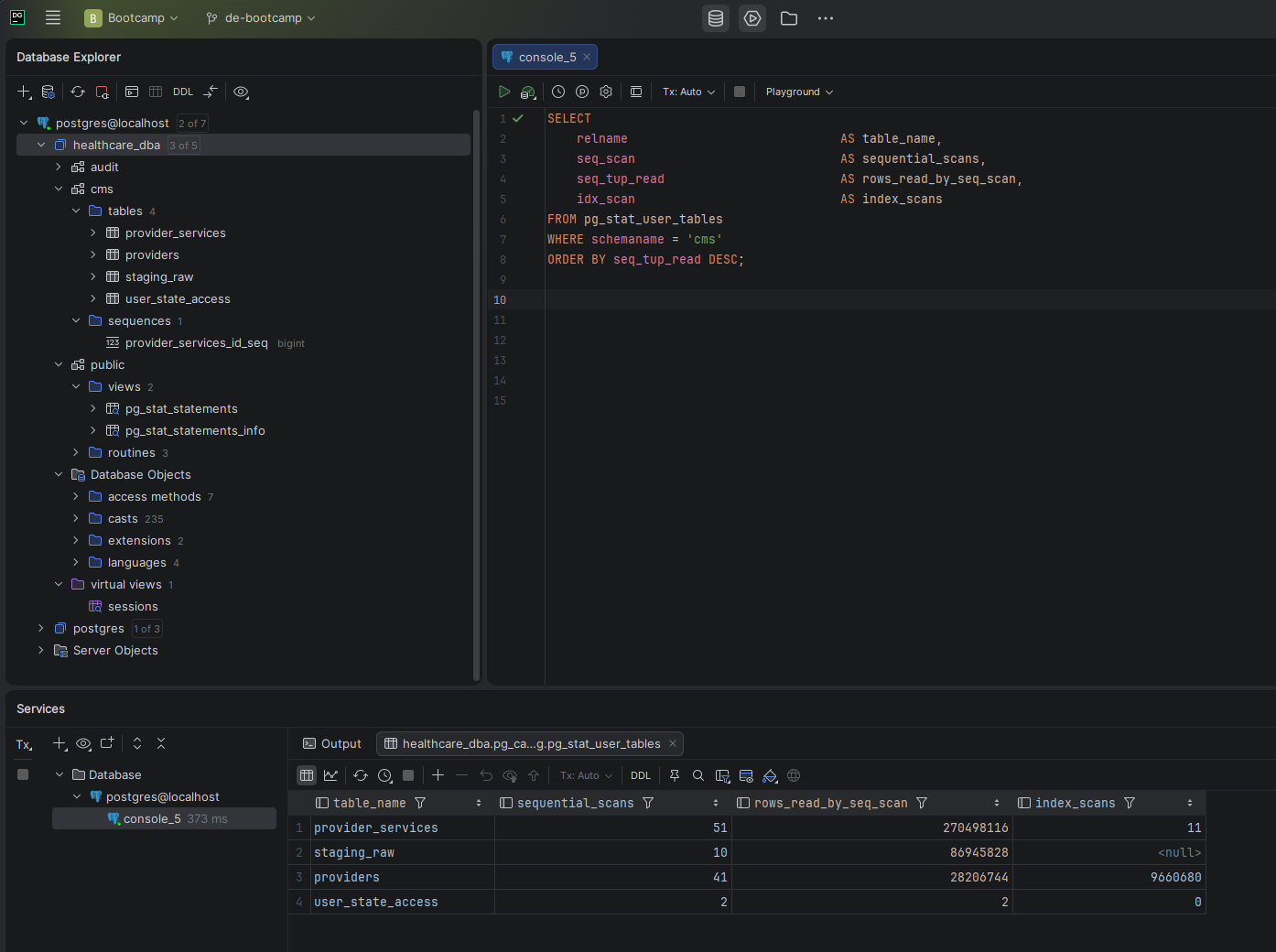
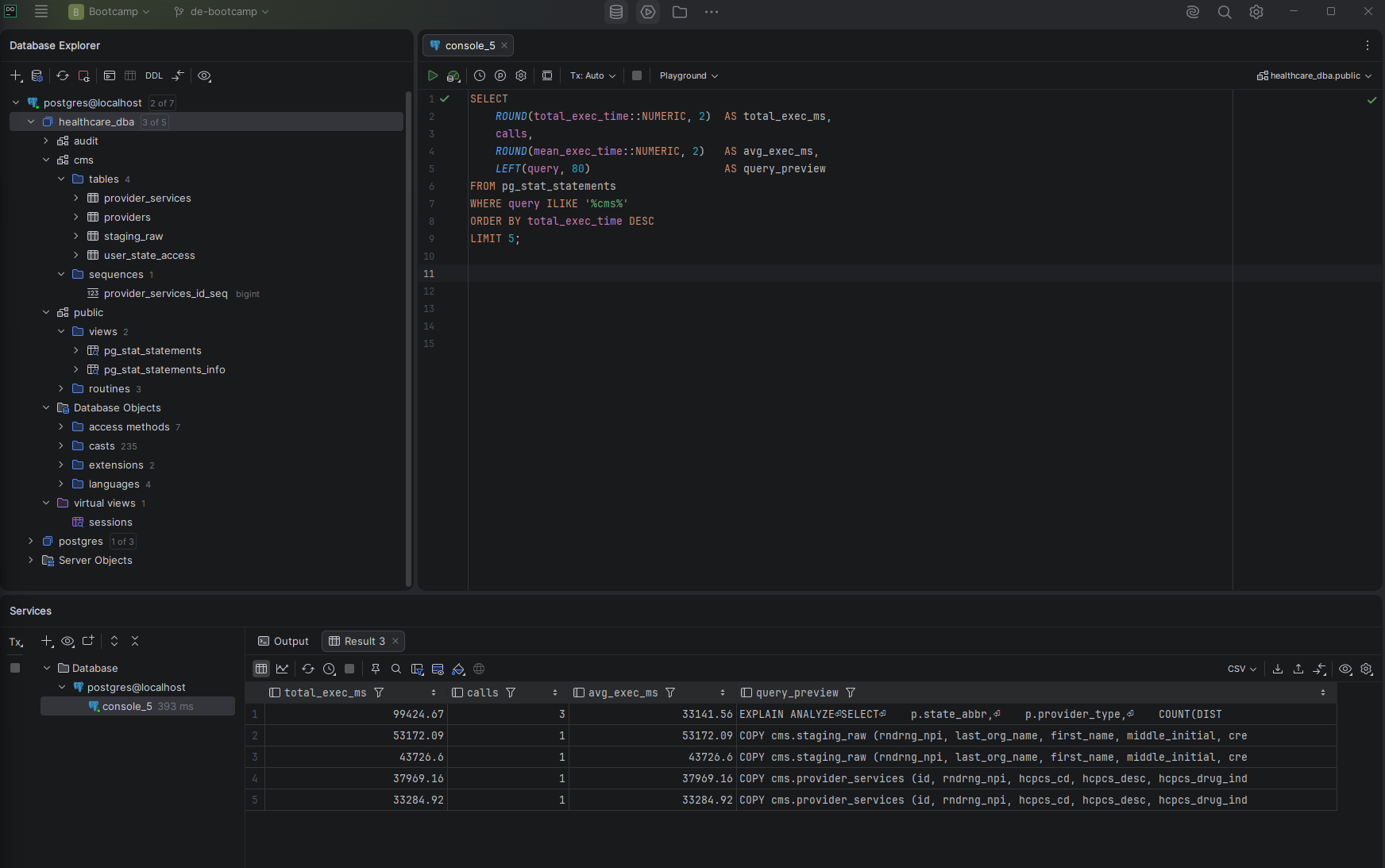
What I Measured First
The first thing I did was establish storage baselines — total database size, individual table sizes, and the index inventory. This tells me what I'm working with before any optimization decisions are made.
| Table | Total Size | Table Size | Index Size |
|---|---|---|---|
| staging_raw | 3,305 MB | 3,304 MB | 0 bytes |
| provider_services | 1,772 MB | 1,564 MB | 207 MB |
| providers | 298 MB | 263 MB | 35 MB |
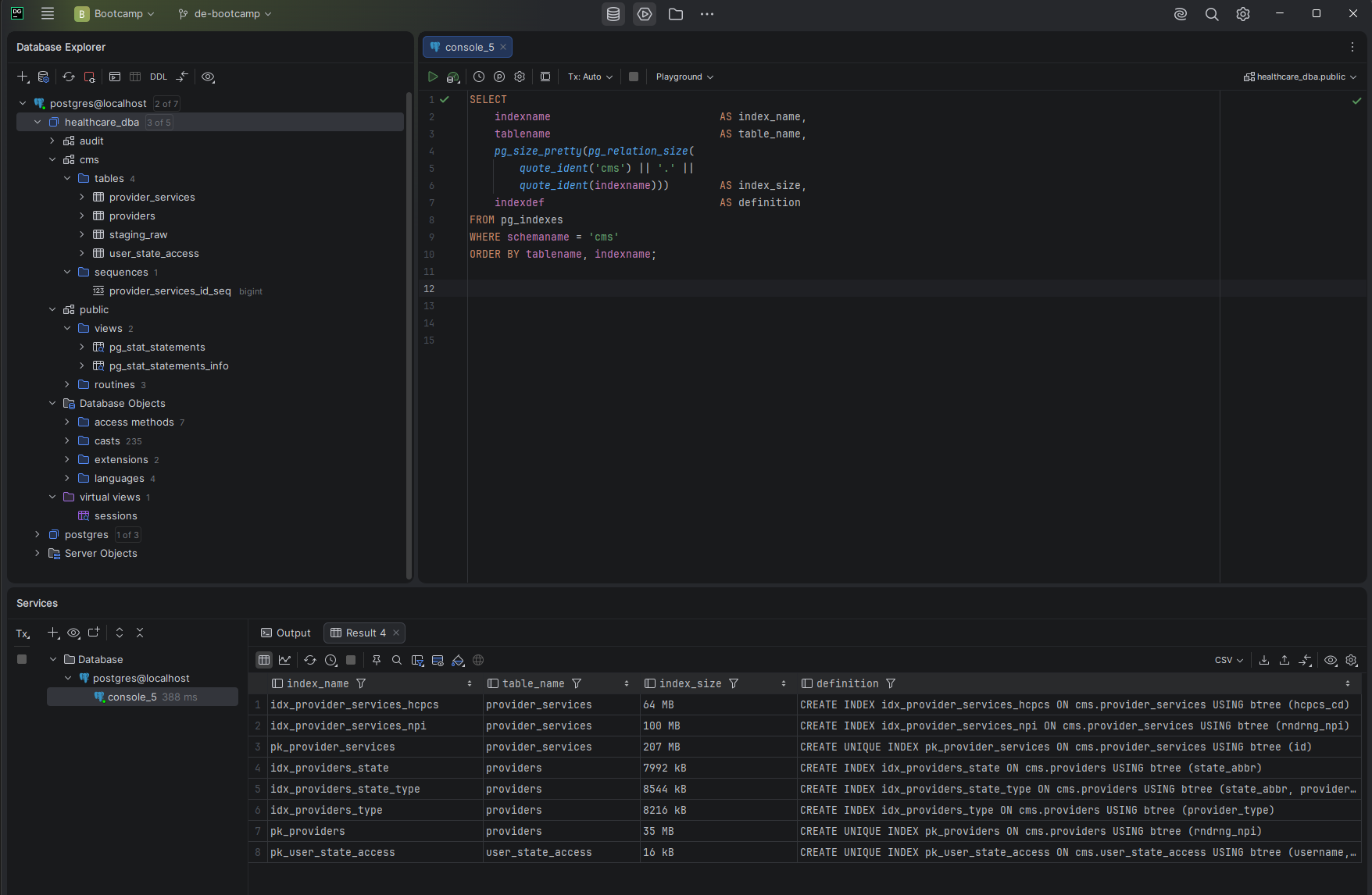
The key observation here: both production tables have only their primary key indexes. No analytical indexes exist on any filter, join, or group-by columns. Every analytical query is going to do a full sequential scan.
Screenshot — Index inventory before optimization
Only two indexes exist — both primary keys. No analytical indexes anywhere in the cms schema.