Results
Data Loaded & Validated
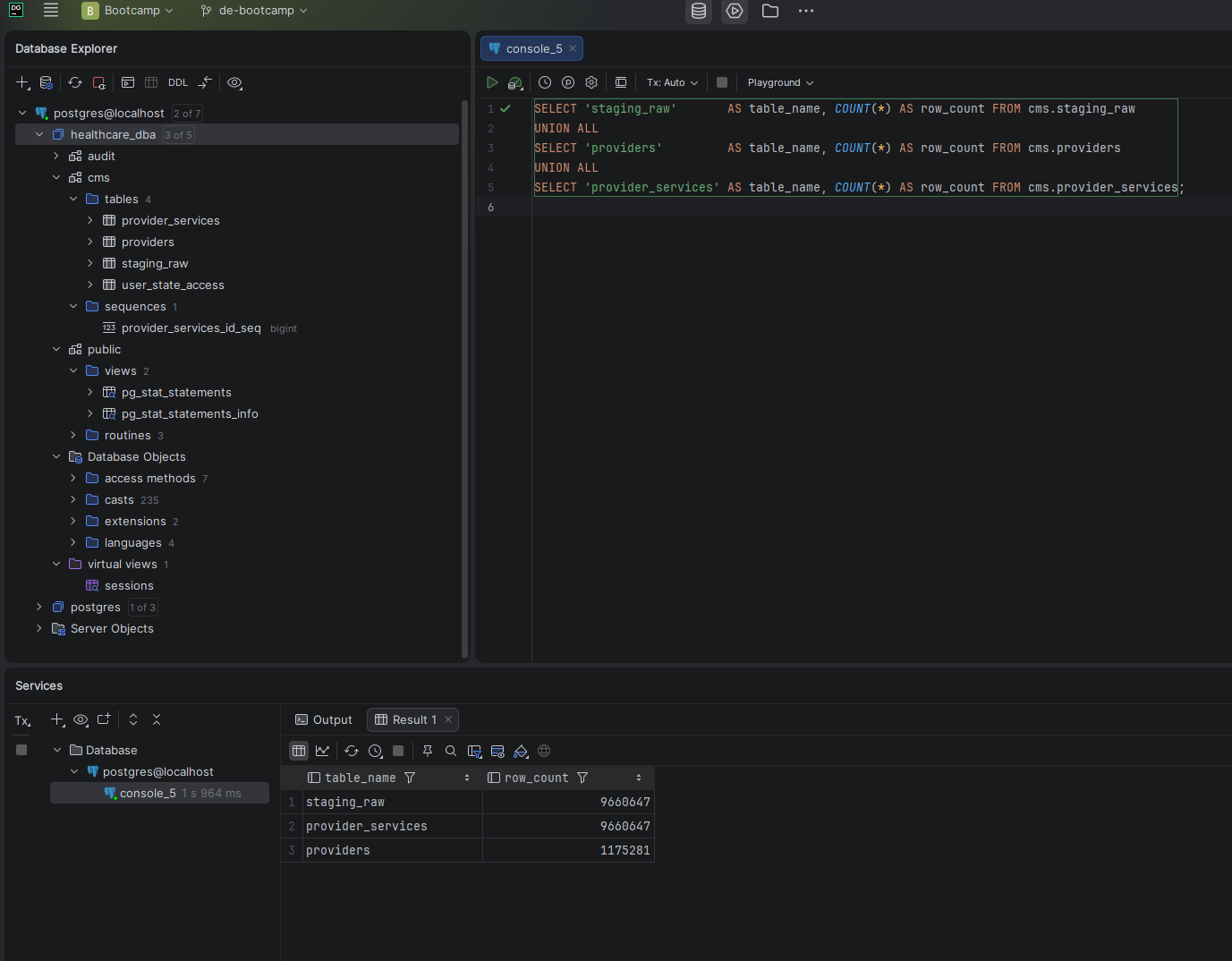
Row Count Verification
After loading I verified row counts across all three tables to confirm the staging table and services table match exactly, and the providers table correctly deduplicated to unique NPIs.
Screenshot — Row counts across all tables
All three tables confirmed — 9,660,647 service rows, 1,175,281 unique providers
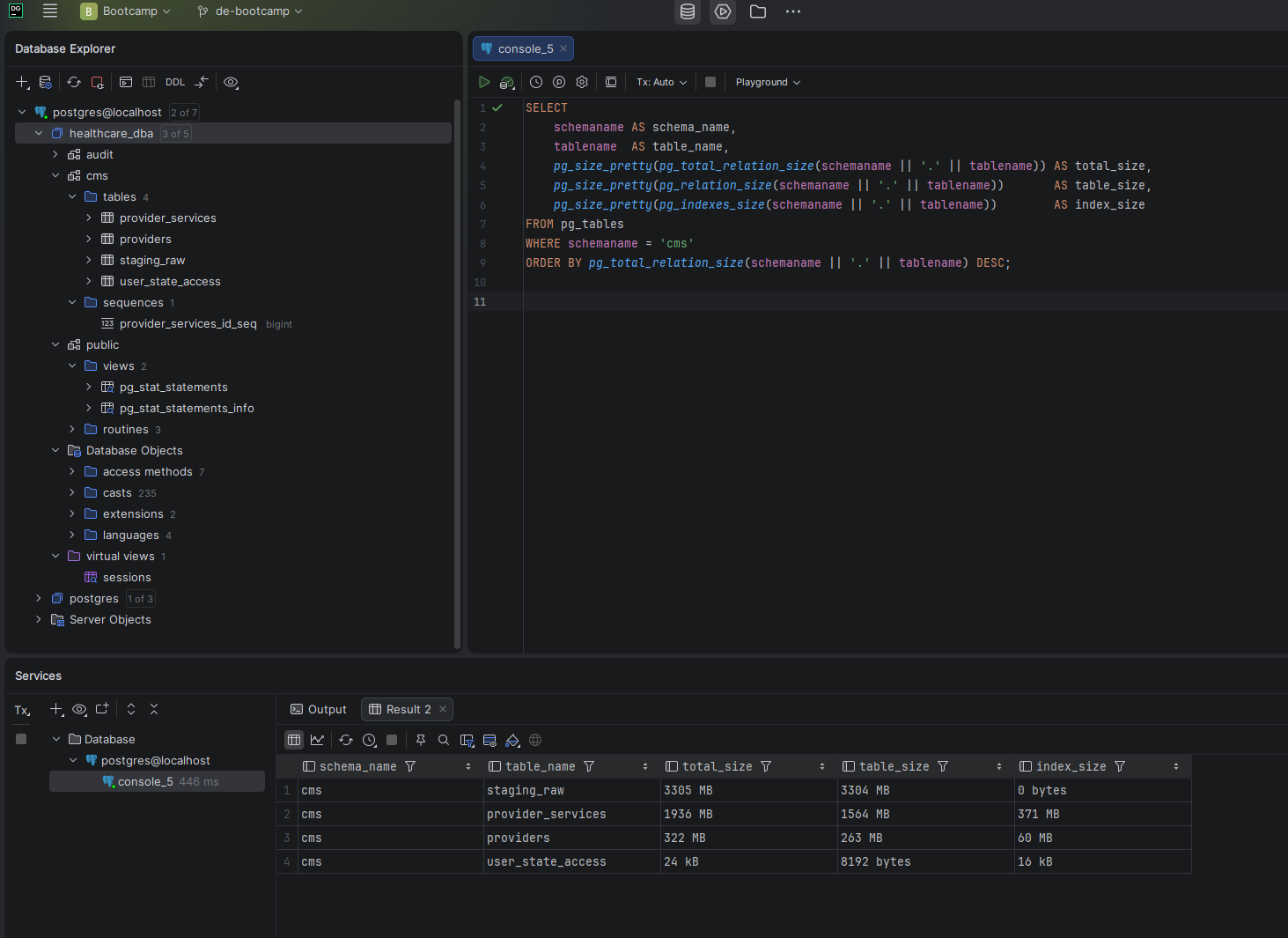
Screenshot — Table sizes after load
Total database size: 5,571 MB — staging_raw at 3.3 GB, provider_services at 1.7 GB, providers at 298 MB
Validation Results
| Check | Result |
|---|---|
| Null NPIs in providers | 0 |
| Orphaned service rows | 0 |
| Null HCPCS codes | 0 |
| Null beneficiary counts | 0 |
| Min Medicare payment | $0.00 |
| Max Medicare payment | $42,059.52 |
| Avg Medicare payment | $82.99 |
| Total Medicare payments | $801,745,767.09 |